 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Effectiveness of Compact Biomedical Transformers
Paper and Code
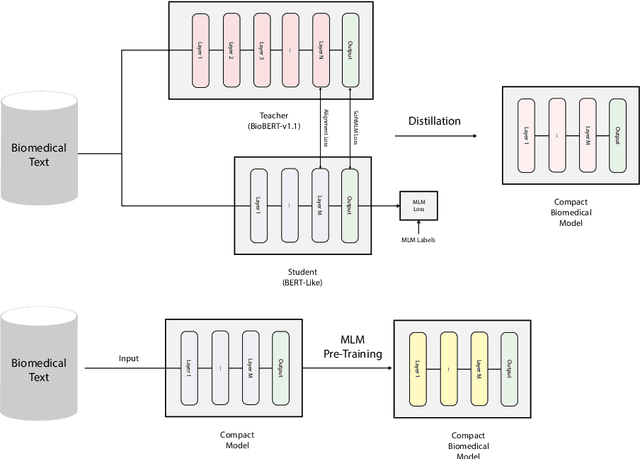
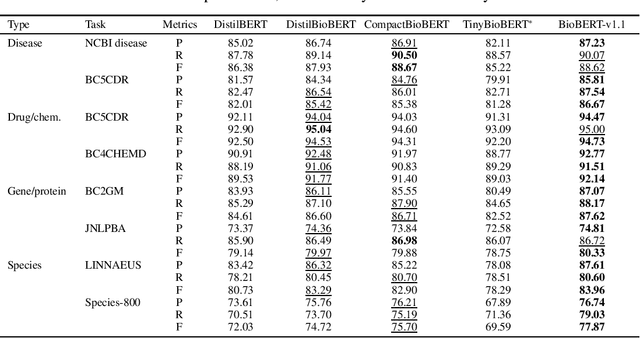
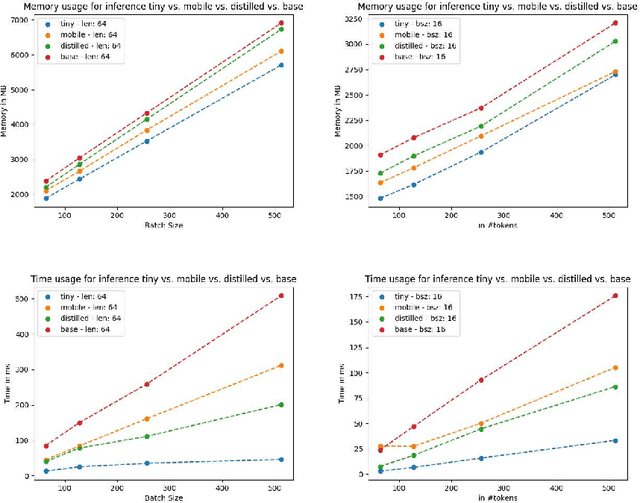
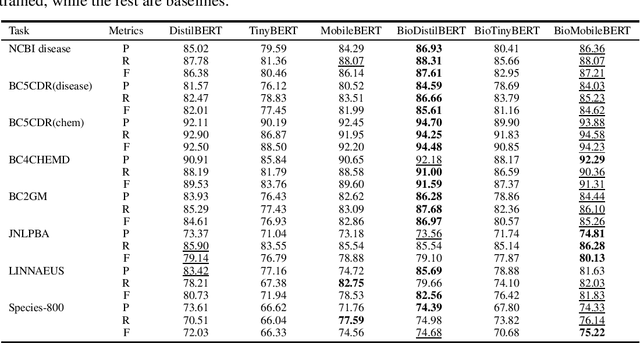
Language models pre-trained on biomedical corpora, such as BioBERT, have recently shown promising results on downstream biomedical tasks. Many existing pre-trained models, on the other hand, are resource-intensive and computationally heavy owing to factors such as embedding size, hidden dimension, and number of layers. The natural language processing (NLP) community has developed numerous strategies to compress these models utilising techniques such as pruning, quantisation, and knowledge distillation, resulting in models that are considerably faster, smaller, and subsequently easier to use in practice. By the same token, in this paper we introduce six lightweight models, namely, BioDistilBERT, BioTinyBERT, BioMobileBERT, DistilBioBERT, TinyBioBERT, and CompactBioBERT which are obtained either by knowledge distillation from a biomedical teacher or continual learning on the Pubmed dataset via the Masked Language Modelling (MLM) objective. We evaluate all of our models on three biomedical tasks and compare them with BioBERT-v1.1 to create efficient lightweight models that perform on par with their larger counterparts. All the models will be publicly available on our Huggingface profile at https://huggingface.co/nlpie and the codes used to run the experiments will be available at https://github.com/nlpie-research/Compact-Biomedical-Transformers.