Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Connection Between Adversarial Robustness and Saliency Map Interpretability
Paper and Code

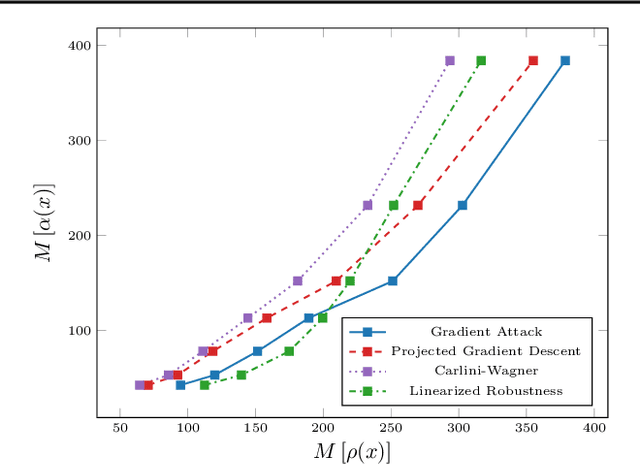
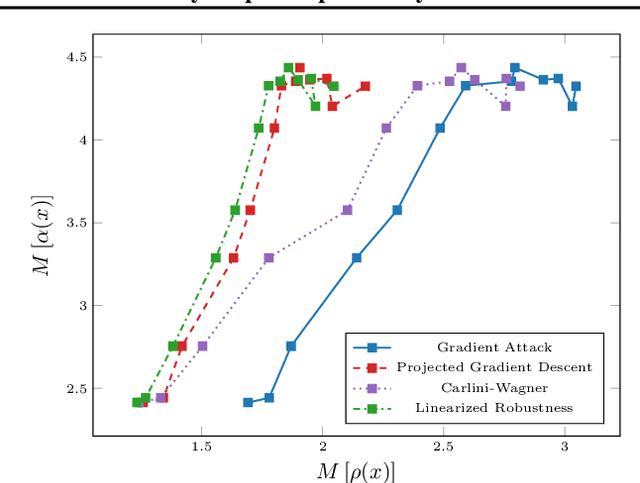
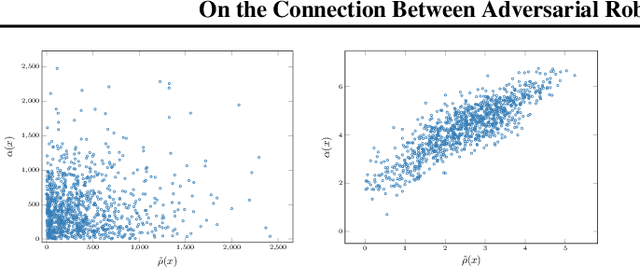
Recent studies on the adversarial vulnerability of neural networks have shown that models trained to be more robust to adversarial attacks exhibit more interpretable saliency maps than their non-robust counterparts. We aim to quantify this behavior by considering the alignment between input image and saliency map. We hypothesize that as the distance to the decision boundary grows,so does the alignment. This connection is strictly true in the case of linear models. We confirm these theoretical findings with experiments based on models trained with a local Lipschitz regularization and identify where the non-linear nature of neural networks weakens the relation.
* 12 pages, accepted for publication at the 36th International
Conference on Machine Learning 2019
View paper on