 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Analysis of Trajectories of Gradient Descent in the Optimization of Deep Neural Networks
Paper and Code
Jul 21, 2018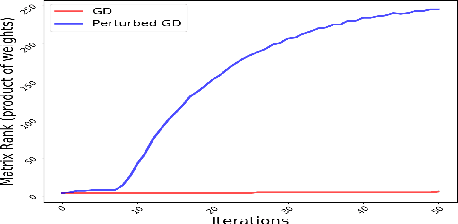
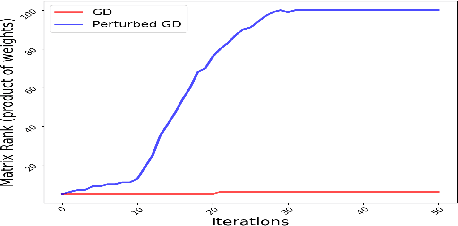
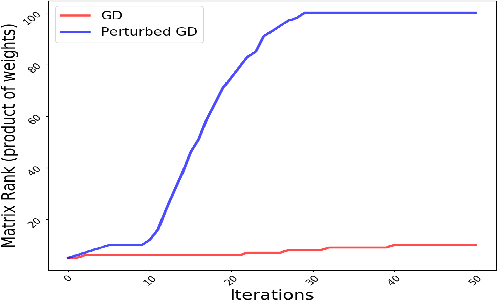
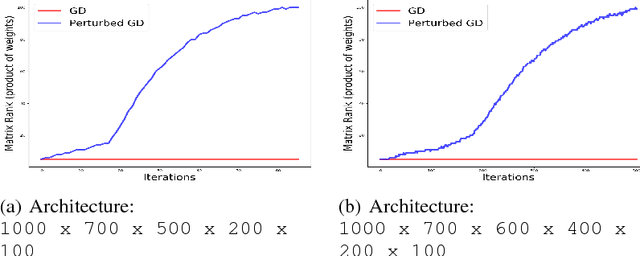
Theoretical analysis of the error landscape of deep neural networks has garnered significant interest in recent years. In this work, we theoretically study the importance of noise in the trajectories of gradient descent towards optimal solutions in multi-layer neural networks. We show that adding noise (in different ways) to a neural network while training increases the rank of the product of weight matrices of a multi-layer linear neural network. We thus study how adding noise can assist reaching a global optimum when the product matrix is full-rank (under certain conditions). We establish theoretical foundations between the noise induced into the neural network - either to the gradient, to the architecture, or to the input/output to a neural network - and the rank of product of weight matrices. We corroborate our theoretical findings with empirical results.