 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Target Segmentation for Direct Speech Translation
Paper and Code
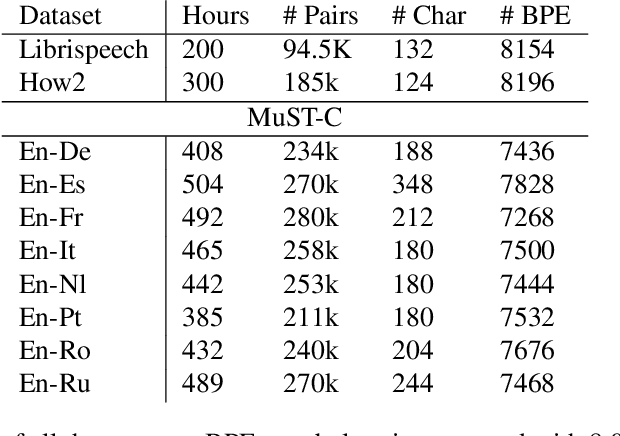
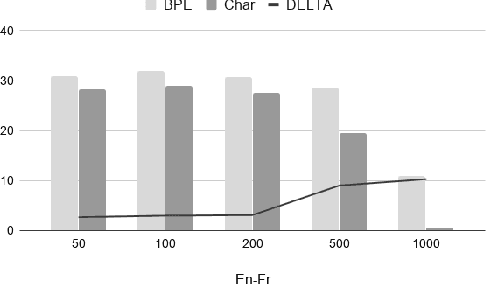

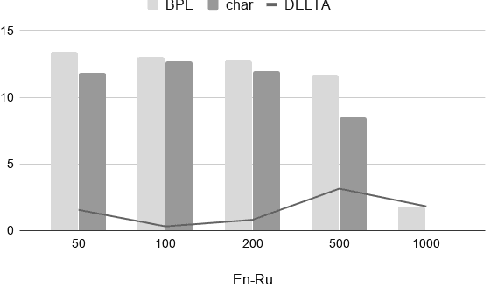
Recent studies on direct speech translation show continuous improvements by means of data augmentation techniques and bigger deep learning models. While these methods are helping to close the gap between this new approach and the more traditional cascaded one, there are many incongruities among different studies that make it difficult to assess the state of the art. Surprisingly, one point of discussion is the segmentation of the target text. Character-level segmentation has been initially proposed to obtain an open vocabulary, but it results on long sequences and long training time. Then, subword-level segmentation became the state of the art in neural machine translation as it produces shorter sequences that reduce the training time, while being superior to word-level models. As such, recent works on speech translation started using target subwords despite the initial use of characters and some recent claims of better results at the character level. In this work, we perform an extensive comparison of the two methods on three benchmarks covering 8 language directions and multilingual training. Subword-level segmentation compares favorably in all settings, outperforming its character-level counterpart in a range of 1 to 3 BLEU points.