 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Sequential Bayesian Inference for Continual Learning
Paper and Code
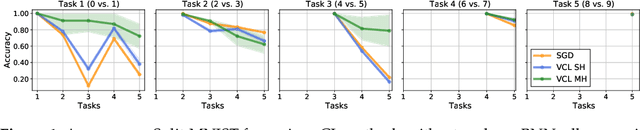



Sequential Bayesian inference can be used for continual learning to prevent catastrophic forgetting of past tasks and provide an informative prior when learning new tasks. We revisit sequential Bayesian inference and test whether having access to the true posterior is guaranteed to prevent catastrophic forgetting in Bayesian neural networks. To do this we perform sequential Bayesian inference using Hamiltonian Monte Carlo. We propagate the posterior as a prior for new tasks by fitting a density estimator on Hamiltonian Monte Carlo samples. We find that this approach fails to prevent catastrophic forgetting demonstrating the difficulty in performing sequential Bayesian inference in neural networks. From there we study simple analytical examples of sequential Bayesian inference and CL and highlight the issue of model misspecification which can lead to sub-optimal continual learning performance despite exact inference. Furthermore, we discuss how task data imbalances can cause forgetting. From these limitations, we argue that we need probabilistic models of the continual learning generative process rather than relying on sequential Bayesian inference over Bayesian neural network weights. In this vein, we also propose a simple baseline called Prototypical Bayesian Continual Learning, which is competitive with state-of-the-art Bayesian continual learning methods on class incremental continual learning vision benchmarks.