 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Measuring Excess Capacity in Neural Networks
Paper and Code
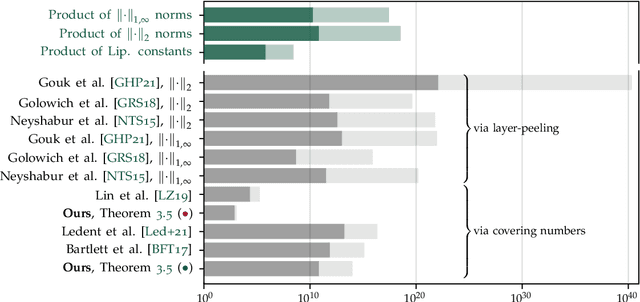
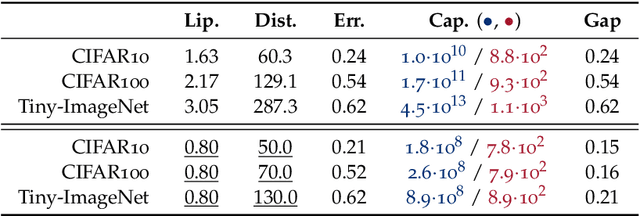
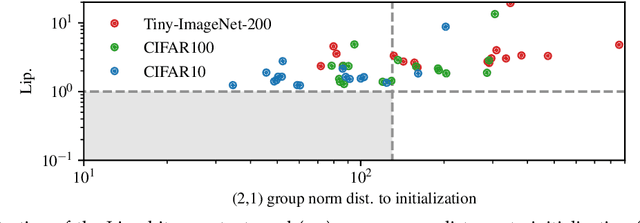
We study the excess capacity of deep networks in the context of supervised classification. That is, given a capacity measure of the underlying hypothesis class -- in our case, Rademacher complexity -- how much can we (a-priori) constrain this class while maintaining an empirical error comparable to the unconstrained setting. To assess excess capacity in modern architectures, we first extend an existing generalization bound to accommodate function composition and addition, as well as the specific structure of convolutions. This then facilitates studying residual networks through the lens of the accompanying capacity measure. The key quantities driving this measure are the Lipschitz constants of the layers and the (2,1) group norm distance to the initializations of the convolution weights. We show that these quantities (1) can be kept surprisingly small and, (2) since excess capacity unexpectedly increases with task difficulty, this points towards an unnecessarily large capacity of unconstrained models.