 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Detecting Adversarial Perturbations
Paper and Code
Feb 21, 2017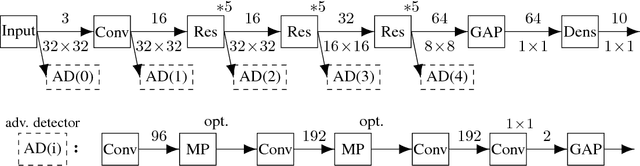



Machine learning and deep learning in particular has advanced tremendously on perceptual tasks in recent years. However, it remains vulnerable against adversarial perturbations of the input that have been crafted specifically to fool the system while being quasi-imperceptible to a human. In this work, we propose to augment deep neural networks with a small "detector" subnetwork which is trained on the binary classification task of distinguishing genuine data from data containing adversarial perturbations. Our method is orthogonal to prior work on addressing adversarial perturbations, which has mostly focused on making the classification network itself more robust. We show empirically that adversarial perturbations can be detected surprisingly well even though they are quasi-imperceptible to humans. Moreover, while the detectors have been trained to detect only a specific adversary, they generalize to similar and weaker adversaries. In addition, we propose an adversarial attack that fools both the classifier and the detector and a novel training procedure for the detector that counteracts this attack.