 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-Average KL-Privacy and its equivalence to Generalization for Max-Entropy Mechanisms
Paper and Code
May 08, 2016
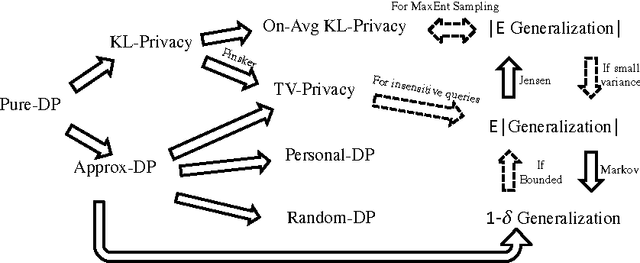
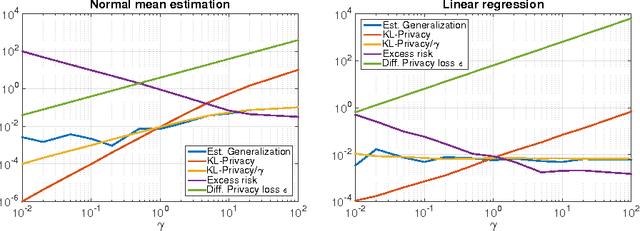
We define On-Average KL-Privacy and present its properties and connections to differential privacy, generalization and information-theoretic quantities including max-information and mutual information. The new definition significantly weakens differential privacy, while preserving its minimalistic design features such as composition over small group and multiple queries as well as closeness to post-processing. Moreover, we show that On-Average KL-Privacy is **equivalent** to generalization for a large class of commonly-used tools in statistics and machine learning that samples from Gibbs distributions---a class of distributions that arises naturally from the maximum entropy principle. In addition, a byproduct of our analysis yields a lower bound for generalization error in terms of mutual information which reveals an interesting interplay with known upper bounds that use the same quantity.