 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn architectural choices in deep learning: From network structure to gradient convergence and parameter estimation
Paper and Code
Feb 28, 2017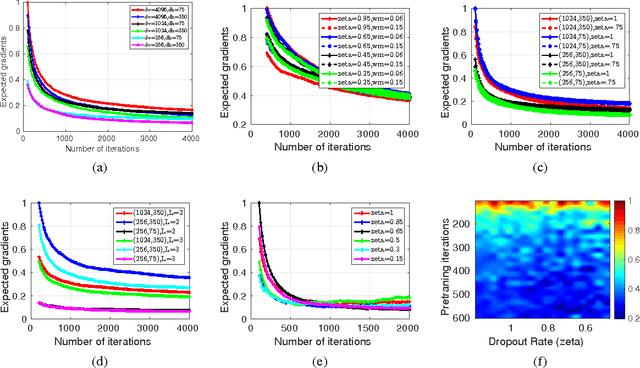

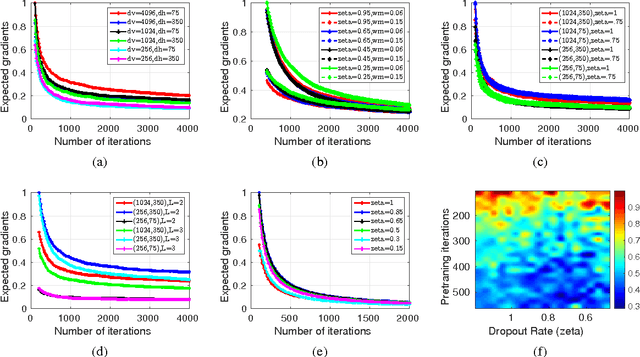
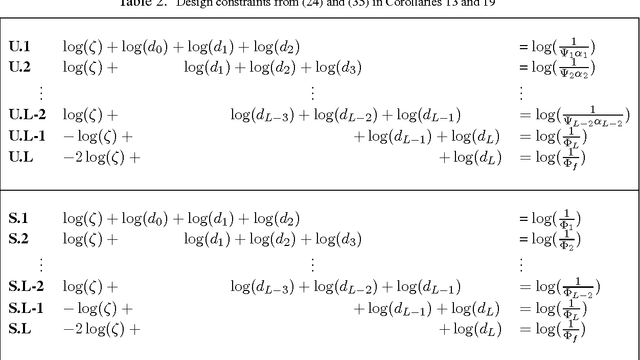
We study mechanisms to characterize how the asymptotic convergence of backpropagation in deep architectures, in general, is related to the network structure, and how it may be influenced by other design choices including activation type, denoising and dropout rate. We seek to analyze whether network architecture and input data statistics may guide the choices of learning parameters and vice versa. Given the broad applicability of deep architectures, this issue is interesting both from theoretical and a practical standpoint. Using properties of general nonconvex objectives (with first-order information), we first build the association between structural, distributional and learnability aspects of the network vis-\`a-vis their interaction with parameter convergence rates. We identify a nice relationship between feature denoising and dropout, and construct families of networks that achieve the same level of convergence. We then derive a workflow that provides systematic guidance regarding the choice of network sizes and learning parameters often mediated4 by input statistics. Our technical results are corroborated by an extensive set of evaluations, presented in this paper as well as independent empirical observations reported by other groups. We also perform experiments showing the practical implications of our framework for choosing the best fully-connected design for a given problem.