 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniCreator: Self-Supervised Unified Generation with Universal Editing
Paper and Code
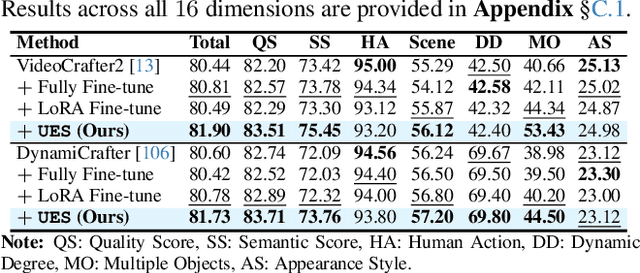
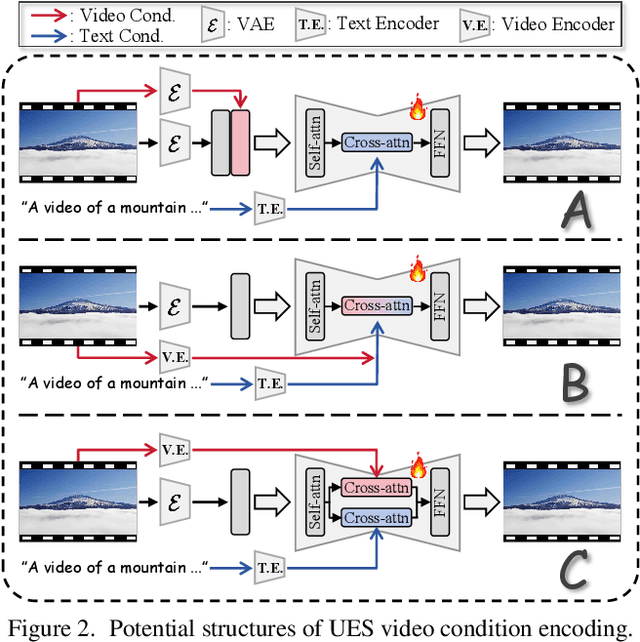
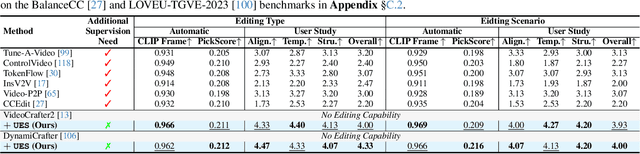

We introduce OmniCreator, a novel framework that can conduct text-prompted unified (image+video) generation as well as editing all in one place. OmniCreator acquires generative and universal editing capabilities in a self-supervised manner, taking original text-video pairs as conditions while utilizing the same video as a denoising target to learn the semantic correspondence between video and text. During inference, when presented with a text prompt and a video, OmniCreator is capable of generating a target that is faithful to both, achieving a universal editing effect that is unconstrained as opposed to existing editing work that primarily focuses on certain editing types or relies on additional controls (e.g., structural conditions, attention features, or DDIM inversion). On the other hand, when presented with a text prompt only, OmniCreator becomes generative, producing high-quality video as a result of the semantic correspondence learned. Importantly, we found that the same capabilities extend to images as is, making OmniCreator a truly unified framework. Further, due to the lack of existing generative video editing benchmarks, we introduce the OmniBench-99 dataset, designed to evaluate the performance of generative video editing models comprehensively. Extensive experiments demonstrate that OmniCreator exhibits substantial superiority over all other models.