 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Learning of Counterfactual Perception as Prediction for Real-World Robotic Reinforcement Learning
Paper and Code
Nov 11, 2020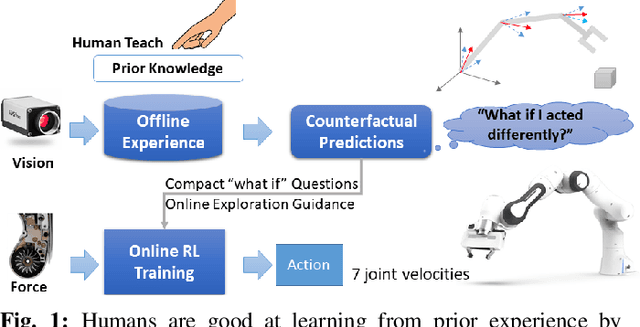
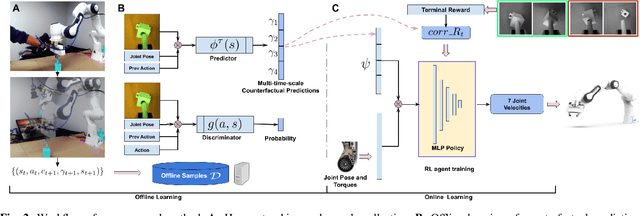
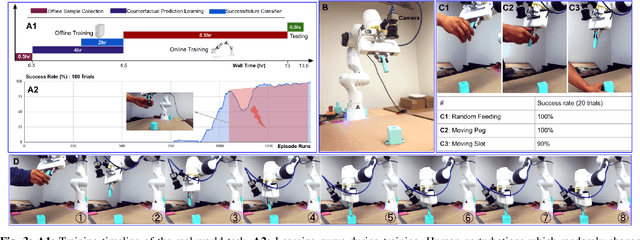

We propose a method for offline learning of counterfactual predictions to address real world robotic reinforcement learning challenges. The proposed method encodes action-oriented visual observations as several "what if" questions learned offline from prior experience using reinforcement learning methods. These "what if" questions counterfactually predict how action-conditioned observation would evolve on multiple temporal scales if the agent were to stick to its current action. We show that combining these offline counterfactual predictions along with online in-situ observations (e.g. force feedback) allows efficient policy learning with only a sparse terminal (success/failure) reward. We argue that the learned predictions form an effective representation of the visual task, and guide the online exploration towards high-potential success interactions (e.g. contact-rich regions). Experiments were conducted in both simulation and real-world scenarios for evaluation. Our results demonstrate that it is practical to train a reinforcement learning agent to perform real-world fine manipulation in about half a day, without hand engineered perception systems or calibrated instrumentation. Recordings of the real robot training can be found via https://sites.google.com/view/realrl.