Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"None of the Above":Measure Uncertainty in Dialog Response Retrieval
Paper and Code
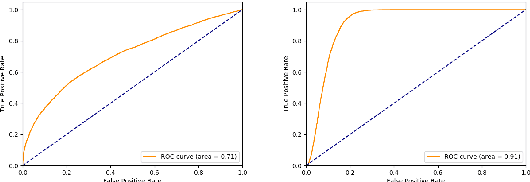
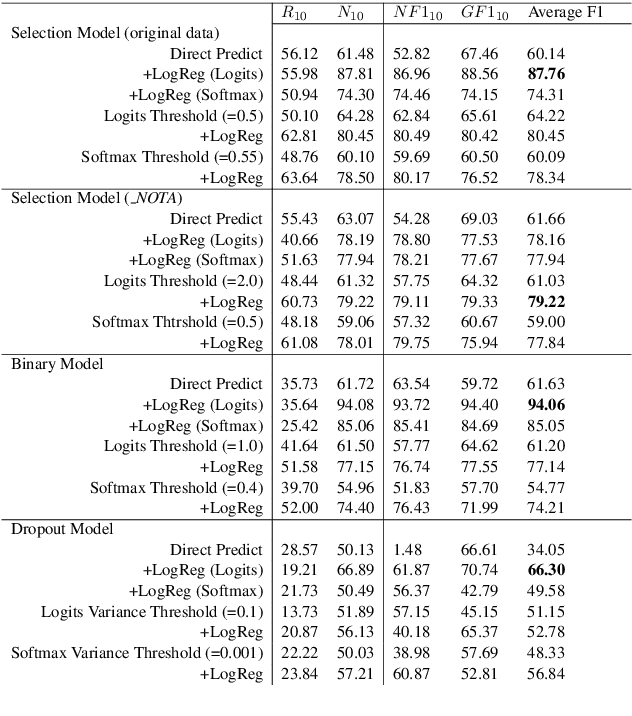
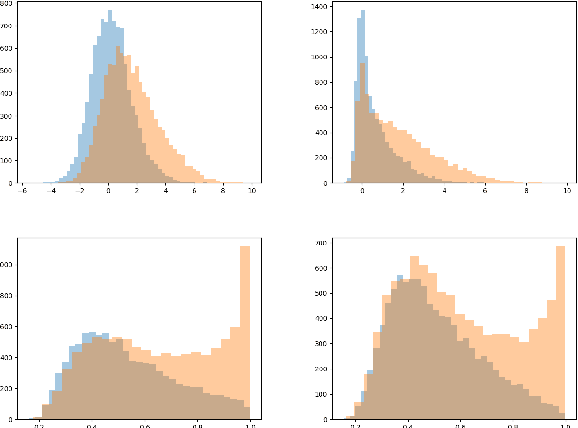
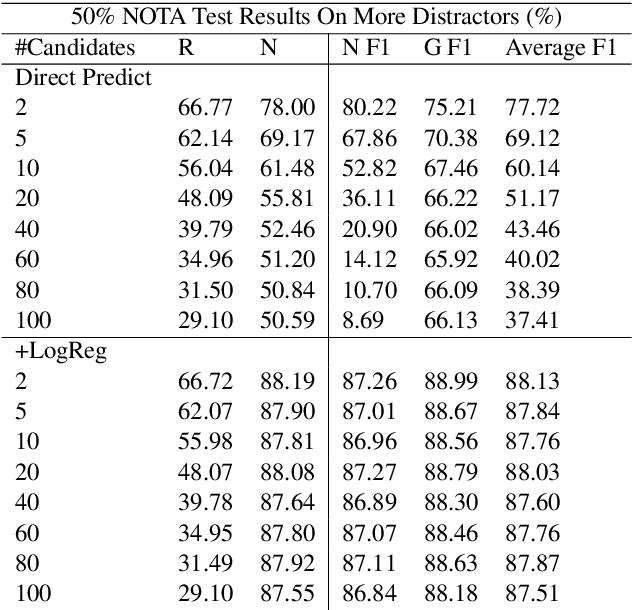
This paper discusses the importance of uncovering uncertainty in end-to-end dialog tasks, and presents our experimental results on uncertainty classification on the Ubuntu Dialog Corpus. We show that, instead of retraining models for this specific purpose, the original retrieval model's underlying confidence concerning the best prediction can be captured with trivial additional computation.
View paper on