 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Cooperative Inverse Reinforcement Learning
Paper and Code
Nov 03, 2019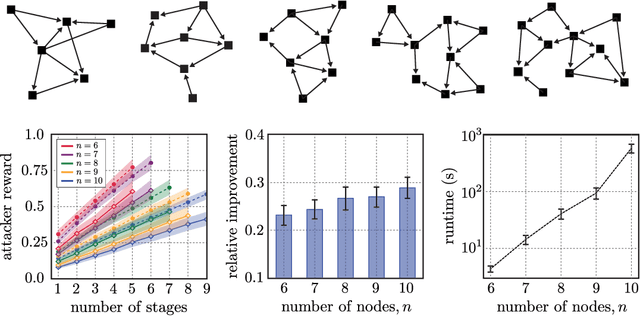
Making decisions in the presence of a strategic opponent requires one to take into account the opponent's ability to actively mask its intended objective. To describe such strategic situations, we introduce the non-cooperative inverse reinforcement learning (N-CIRL) formalism. The N-CIRL formalism consists of two agents with completely misaligned objectives, where only one of the agents knows the true objective function. Formally, we model the N-CIRL formalism as a zero-sum Markov game with one-sided incomplete information. Through interacting with the more informed player, the less informed player attempts to both infer, and act according to, the true objective function. As a result of the one-sided incomplete information, the multi-stage game can be decomposed into a sequence of single-stage games expressed by a recursive formula. Solving this recursive formula yields the value of the N-CIRL game and the more informed player's equilibrium strategy. Another recursive formula, constructed by forming an auxiliary game, termed the dual game, yields the less informed player's strategy. Building upon these two recursive formulas, we develop a computationally tractable algorithm to approximately solve for the equilibrium strategies. Finally, we demonstrate the benefits of our N-CIRL formalism over the existing multi-agent IRL formalism via extensive numerical simulation in a novel cyber security setting.