 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-convex regularization in remote sensing
Paper and Code
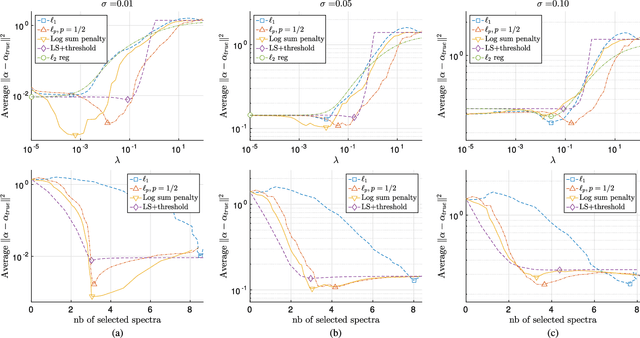
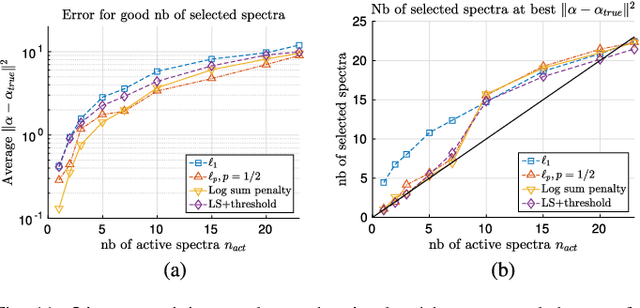
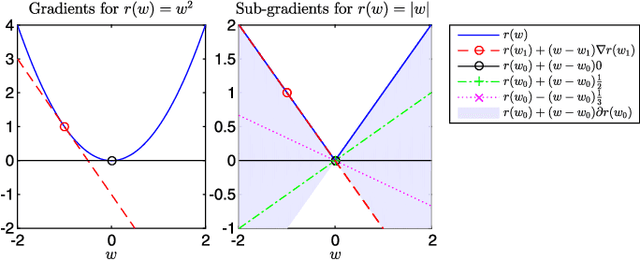
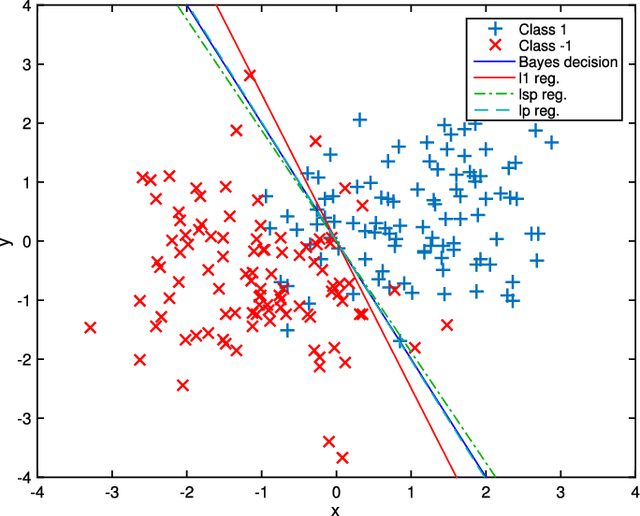
In this paper, we study the effect of different regularizers and their implications in high dimensional image classification and sparse linear unmixing. Although kernelization or sparse methods are globally accepted solutions for processing data in high dimensions, we present here a study on the impact of the form of regularization used and its parametrization. We consider regularization via traditional squared (2) and sparsity-promoting (1) norms, as well as more unconventional nonconvex regularizers (p and Log Sum Penalty). We compare their properties and advantages on several classification and linear unmixing tasks and provide advices on the choice of the best regularizer for the problem at hand. Finally, we also provide a fully functional toolbox for the community.