 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoisy UGC Translation at the Character Level: Revisiting Open-Vocabulary Capabilities and Robustness of Char-Based Models
Paper and Code



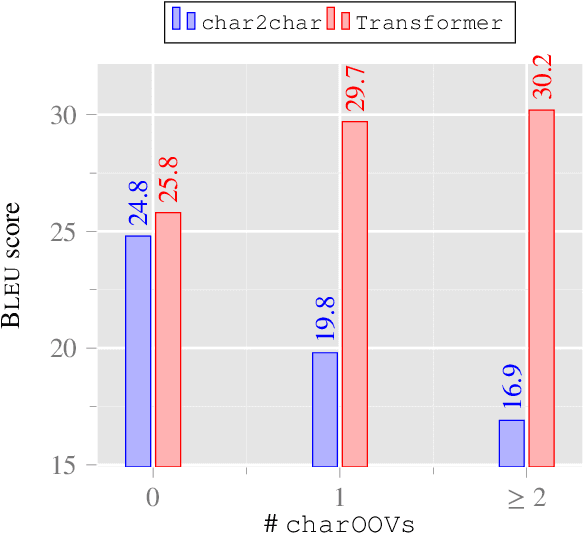
This work explores the capacities of character-based Neural Machine Translation to translate noisy User-Generated Content (UGC) with a strong focus on exploring the limits of such approaches to handle productive UGC phenomena, which almost by definition, cannot be seen at training time. Within a strict zero-shot scenario, we first study the detrimental impact on translation performance of various user-generated content phenomena on a small annotated dataset we developed, and then show that such models are indeed incapable of handling unknown letters, which leads to catastrophic translation failure once such characters are encountered. We further confirm this behavior with a simple, yet insightful, copy task experiment and highlight the importance of reducing the vocabulary size hyper-parameter to increase the robustness of character-based models for machine translation.