 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Free Lunch From Random Feature Ensembles
Paper and Code
Dec 06, 2024
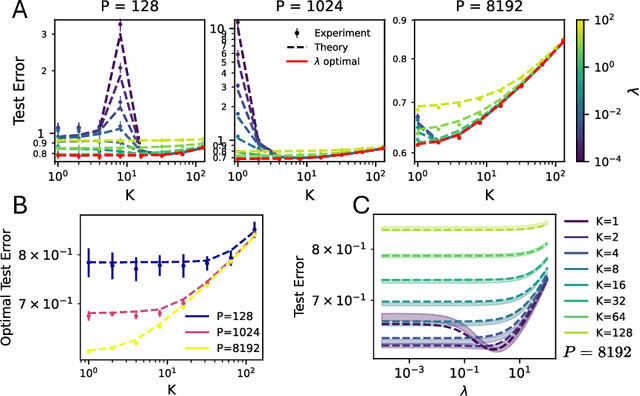

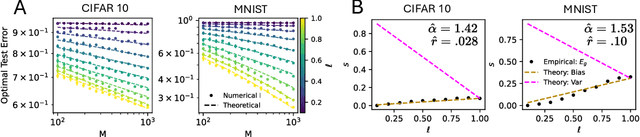
Given a budget on total model size, one must decide whether to train a single, large neural network or to combine the predictions of many smaller networks. We study this trade-off for ensembles of random-feature ridge regression models. We prove that when a fixed number of trainable parameters are partitioned among $K$ independently trained models, $K=1$ achieves optimal performance, provided the ridge parameter is optimally tuned. We then derive scaling laws which describe how the test risk of an ensemble of regression models decays with its total size. We identify conditions on the kernel and task eigenstructure under which ensembles can achieve near-optimal scaling laws. Training ensembles of deep convolutional neural networks on CIFAR-10 and a transformer architecture on C4, we find that a single large network outperforms any ensemble of networks with the same total number of parameters, provided the weight decay and feature-learning strength are tuned to their optimal values.