 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNextformer: A ConvNeXt Augmented Conformer For End-To-End Speech Recognition
Paper and Code
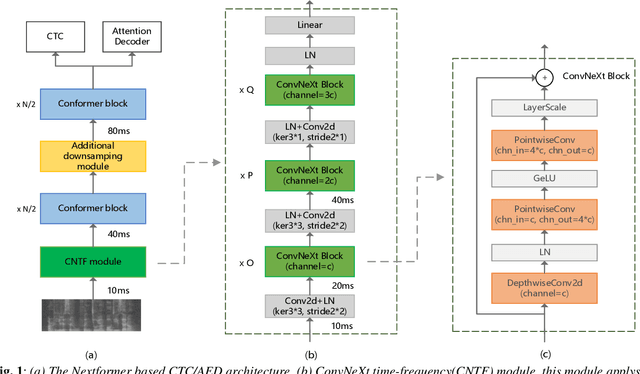
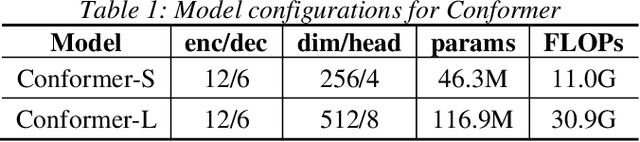
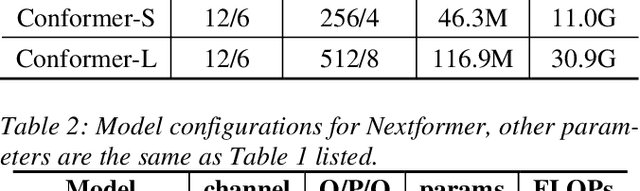
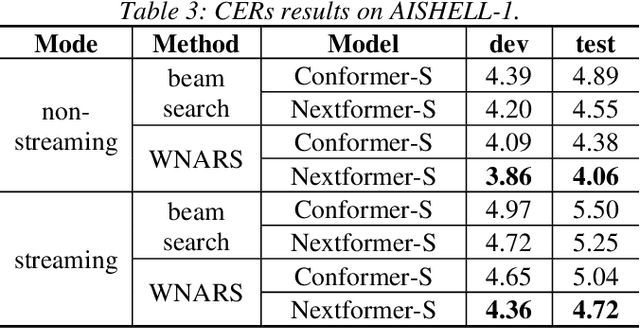
Conformer models have achieved state-of-the-art(SOTA) results in end-to-end speech recognition. However Conformer mainly focuses on temporal modeling while pays less attention on time-frequency property of speech feature. In this paper we augment Conformer with ConvNeXt and propose Nextformer structure. We use stacks of ConvNeXt block to replace the commonly used subsampling module in Conformer for utilizing the information contained in time-frequency speech feature. Besides, we insert an additional downsampling module in middle of Conformer layers to make our model more efficient and accurate. We conduct experiments on two opening datasets, AISHELL-1 and WenetSpeech. On AISHELL-1, compared to Conformer baselines, Nextformer obtains 7.3% and 6.3% relative CER reduction in non-streaming and streaming mode respectively, and on a much larger WenetSpeech dataset, Nextformer gives 5.0%~6.5% and 7.5%~14.6% relative CER reduction in non-streaming and streaming mode, while keep the computational cost FLOPs comparable to Conformer. To the best of our knowledge, the proposed Nextformer model achieves SOTA results on AISHELL-1(CER 4.06%) and WenetSpeech(CER 7.56%/11.29%).