 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNew Vietnamese Corpus for Machine ReadingComprehension of Health News Articles
Paper and Code
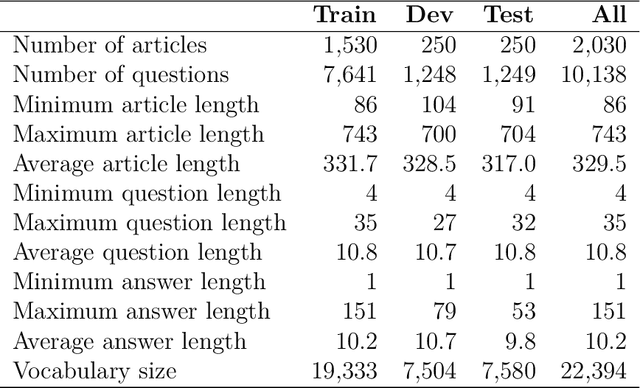
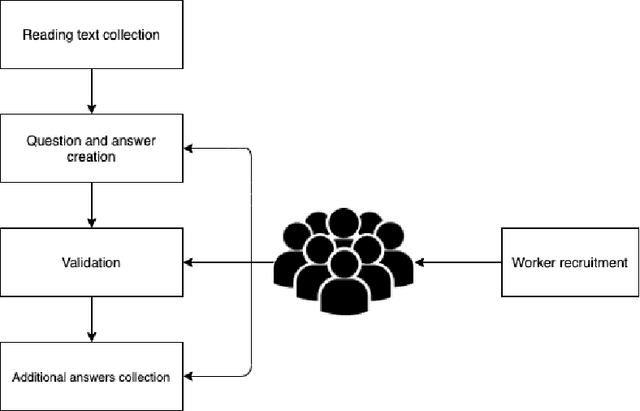
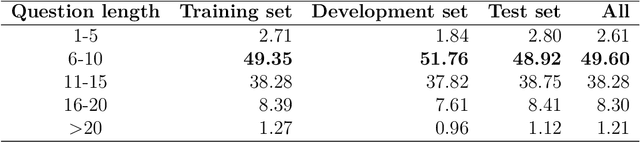
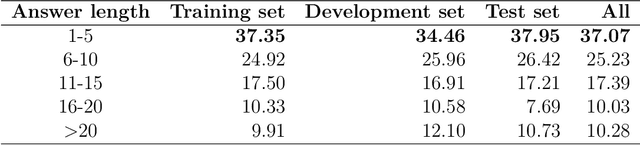
Although over 95 million people in the world speak the Vietnamese language, there are not any large and qualified datasets for automatic reading comprehension. In addition, machine reading comprehension for the health domain offers great potential for practical applications; however, there is still very little machine reading comprehension research in this domain. In this study, we present ViNewsQA as a new corpus for the low-resource Vietnamese language to evaluate models of machine reading comprehension. The corpus comprises 10,138 human-generated question-answer pairs. Crowdworkers created the questions and answers based on a set of over 2,030 online Vietnamese news articles from the VnExpress news website, where the answers comprised spans extracted from the corresponding articles. In particular, we developed a process of creating a corpus for the Vietnamese language. Comprehensive evaluations demonstrated that our corpus requires abilities beyond simple reasoning such as word matching, as well as demanding difficult reasoning similar to inferences based on single-or-multiple-sentence information. We conducted experiments using state-of-the-art methods for machine reading comprehension to obtain the first baseline performance measures, which will be compared with further models' performances. We measured human performance based on the corpus and compared it with several strong neural models. Our experiments showed that the best model was BERT, which achieved an exact match score of 57.57% and F1-score of 76.90% on our corpus. The significant difference between humans and the best model (F1-score of 15.93%) on the test set of our corpus indicates that improvements in ViNewsQA can be explored in future research. Our corpus is freely available on our website in order to encourage the research community to make these improvements.