 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuronal Circuit Policies
Paper and Code
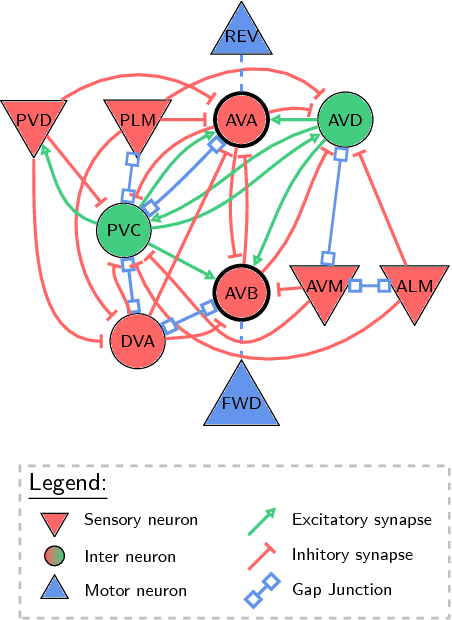

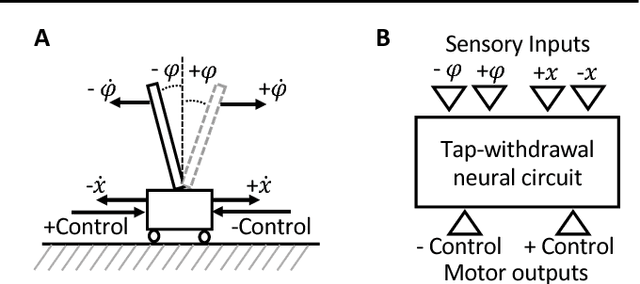

We propose an effective way to create interpretable control agents, by re-purposing the function of a biological neural circuit model, to govern simulated and real world reinforcement learning (RL) test-beds. We model the tap-withdrawal (TW) neural circuit of the nematode, C. elegans, a circuit responsible for the worm's reflexive response to external mechanical touch stimulations, and learn its synaptic and neuronal parameters as a policy for controlling basic RL tasks. We also autonomously park a real rover robot on a pre-defined trajectory, by deploying such neuronal circuit policies learned in a simulated environment. For reconfiguration of the purpose of the TW neural circuit, we adopt a search-based RL algorithm. We show that our neuronal policies perform as good as deep neural network policies with the advantage of realizing interpretable dynamics at the cell level.