 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Residual Flow Fields for Efficient Video Representations
Paper and Code
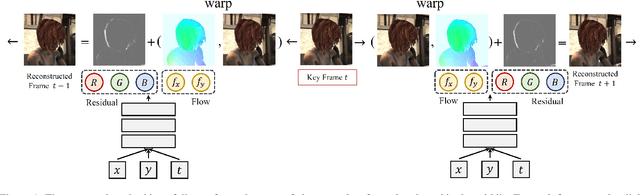
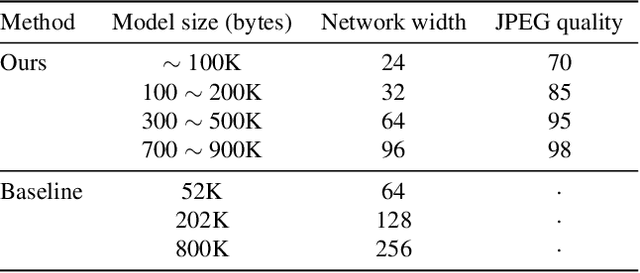
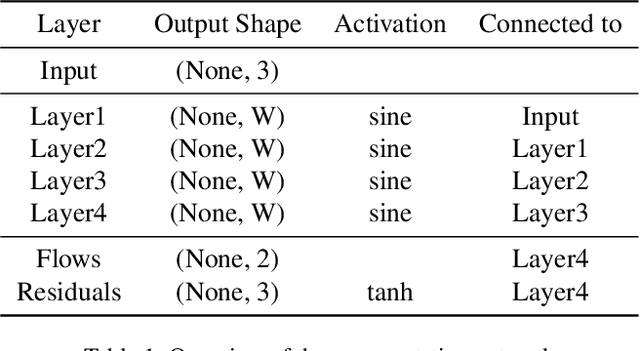
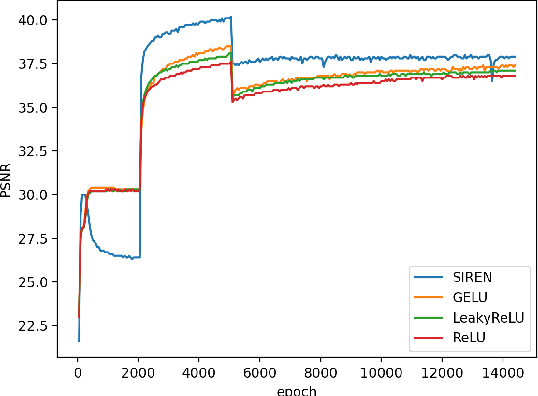
Implicit neural representation (INR) has emerged as a powerful paradigm for representing signals, such as images, videos, 3D shapes, etc. Although it has shown the ability to represent fine details, its efficiency as a data representation has not been extensively studied. In INR, the data is stored in the form of parameters of a neural network and general purpose optimization algorithms do not generally exploit the spatial and temporal redundancy in signals. In this paper, we suggest a novel INR approach to representing and compressing videos by explicitly removing data redundancy. Instead of storing raw RGB colors, we propose Neural Residual Flow Fields (NRFF), using motion information across video frames and residuals that are necessary to reconstruct a video. Maintaining the motion information, which is usually smoother and less complex than the raw signals, requires far fewer parameters. Furthermore, reusing redundant pixel values further improves the network parameter efficiency. Experimental results have shown that the proposed method outperforms the baseline methods by a significant margin. The code is available in https://github.com/daniel03c1/eff_video_representation.