 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural ODEs as Feedback Policies for Nonlinear Optimal Control
Paper and Code
Oct 20, 2022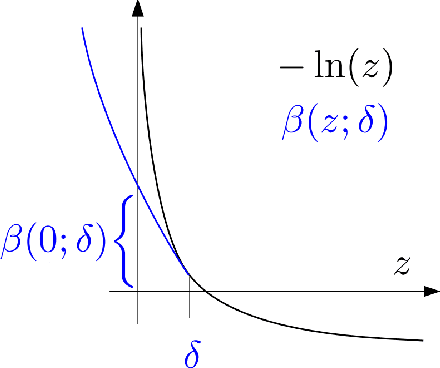
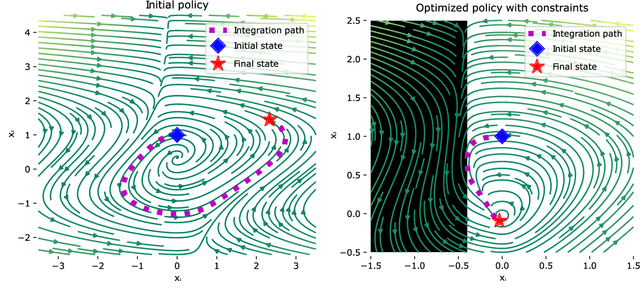
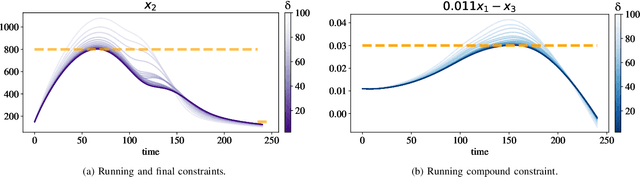

Neural ordinary differential equations (Neural ODEs) model continuous time dynamics as differential equations parametrized with neural networks. Thanks to their modeling flexibility, they have been adopted for multiple tasks where the continuous time nature of the process is specially relevant, as in system identification and time series analysis. When applied in a control setting, it is possible to adapt their use to approximate optimal nonlinear feedback policies. This formulation follows the same approach as policy gradients in reinforcement learning, covering the case where the environment consists of known deterministic dynamics given by a system of differential equations. The white box nature of the model specification allows the direct calculation of policy gradients through sensitivity analysis, avoiding the inexact and inefficient gradient estimation through sampling. In this work we propose the use of a neural control policy posed as a Neural ODE to solve general nonlinear optimal control problems while satisfying both state and control constraints, which are crucial for real world scenarios. Since the state feedback policy partially modifies the model dynamics, the whole space phase of the system is reshaped upon the optimization. This approach is a sensible approximation to the historically intractable closed loop solution of nonlinear control problems that efficiently exploits the availability of a dynamical system model.