 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Exploitation and Exploration of Contextual Bandits
Paper and Code
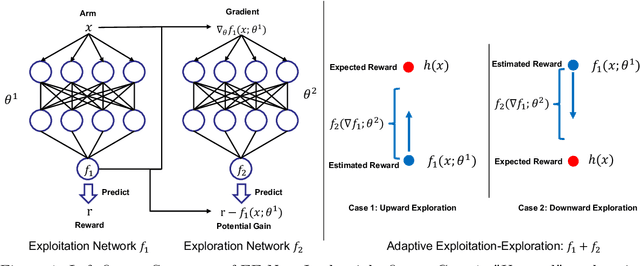

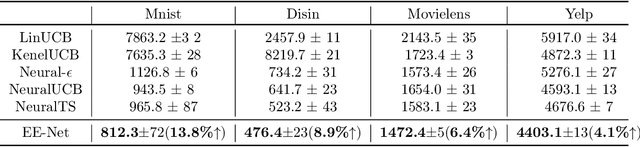
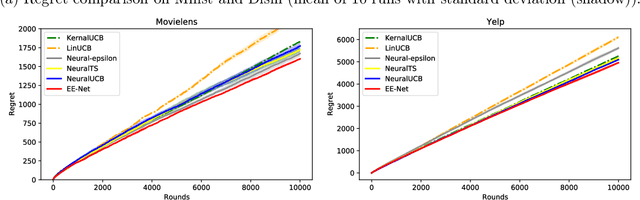
In this paper, we study utilizing neural networks for the exploitation and exploration of contextual multi-armed bandits. Contextual multi-armed bandits have been studied for decades with various applications. To solve the exploitation-exploration trade-off in bandits, there are three main techniques: epsilon-greedy, Thompson Sampling (TS), and Upper Confidence Bound (UCB). In recent literature, a series of neural bandit algorithms have been proposed to adapt to the non-linear reward function, combined with TS or UCB strategies for exploration. In this paper, instead of calculating a large-deviation based statistical bound for exploration like previous methods, we propose, ``EE-Net,'' a novel neural-based exploitation and exploration strategy. In addition to using a neural network (Exploitation network) to learn the reward function, EE-Net uses another neural network (Exploration network) to adaptively learn the potential gains compared to the currently estimated reward for exploration. We provide an instance-based $\widetilde{\mathcal{O}}(\sqrt{T})$ regret upper bound for EE-Net and show that EE-Net outperforms related linear and neural contextual bandit baselines on real-world datasets.