 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetwork Constrained Distributed Dual Coordinate Ascent for Machine Learning
Paper and Code
Oct 30, 2018
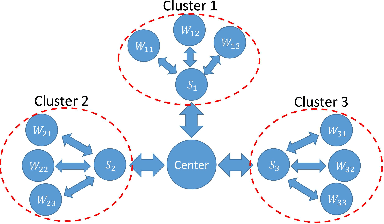
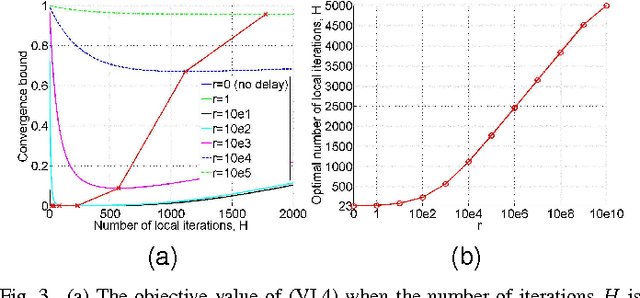
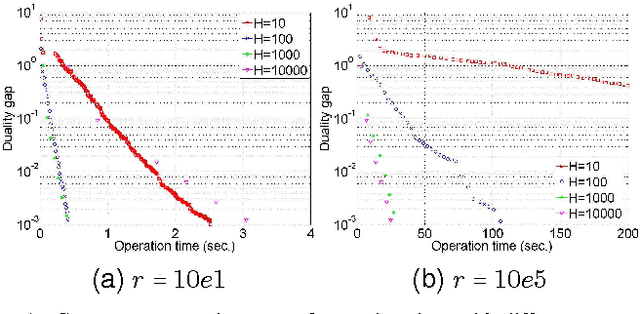
With explosion of data size and limited storage space at a single location, data are often distributed at different locations. We thus face the challenge of performing large-scale machine learning from these distributed data through communication networks. In this paper, we study how the network communication constraints will impact the convergence speed of distributed machine learning optimization algorithms. In particular, we give the convergence rate analysis of the distributed dual coordinate ascent in a general tree structured network. Furthermore, by considering network communication delays, we optimize the network-constrained dual coordinate ascent algorithms to maximize its convergence speed. Our results show that under different network communication delays, to achieve maximum convergence speed, one needs to adopt delay-dependent numbers of local and global iterations for distributed dual coordinate ascent.