 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeRF-Loc: Visual Localization with Conditional Neural Radiance Field
Paper and Code
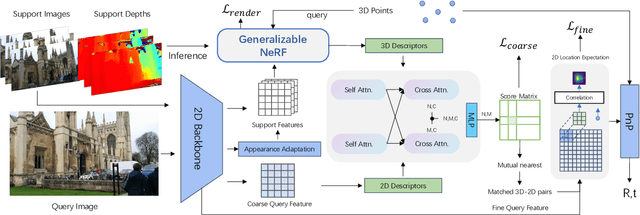



We propose a novel visual re-localization method based on direct matching between the implicit 3D descriptors and the 2D image with transformer. A conditional neural radiance field(NeRF) is chosen as the 3D scene representation in our pipeline, which supports continuous 3D descriptors generation and neural rendering. By unifying the feature matching and the scene coordinate regression to the same framework, our model learns both generalizable knowledge and scene prior respectively during two training stages. Furthermore, to improve the localization robustness when domain gap exists between training and testing phases, we propose an appearance adaptation layer to explicitly align styles between the 3D model and the query image. Experiments show that our method achieves higher localization accuracy than other learning-based approaches on multiple benchmarks. Code is available at \url{https://github.com/JenningsL/nerf-loc}.