 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNarrative Incoherence Detection
Paper and Code
Dec 21, 2020

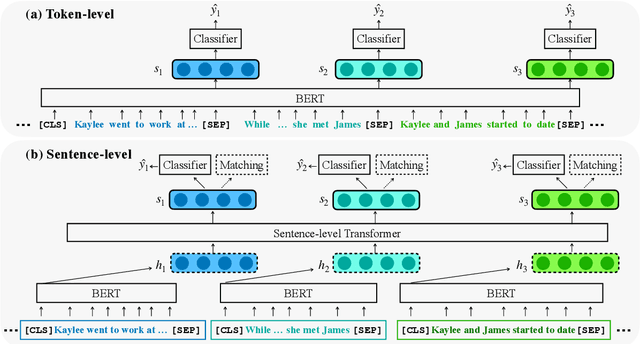
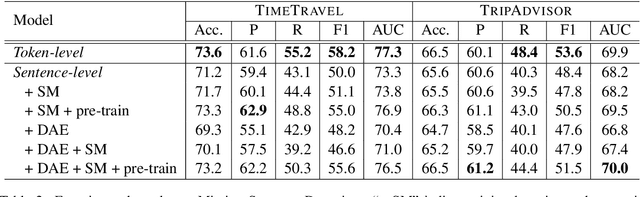
Motivated by the increasing popularity of intelligent editing assistant, we introduce and investigate the task of narrative incoherence detection: Given a (corrupted) long-form narrative, decide whether there exists some semantic discrepancy in the narrative flow. Specifically, we focus on the missing sentence and incoherent sentence detection. Despite its simple setup, this task is challenging as the model needs to understand and analyze a multi-sentence narrative text, and make decisions at the sentence level. As an initial step towards this task, we implement several baselines either directly analyzing the raw text (\textit{token-level}) or analyzing learned sentence representations (\textit{sentence-level}). We observe that while token-level modeling enjoys greater expressive power and hence better performance, sentence-level modeling possesses an advantage in efficiency and flexibility. With pre-training on large-scale data and cycle-consistent sentence embedding, our extended sentence-level model can achieve comparable detection accuracy to the token-level model. As a by-product, such a strategy enables simultaneous incoherence detection and infilling/modification suggestions.