 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeN-Shot Benchmarking of Whisper on Diverse Arabic Speech Recognition
Paper and Code

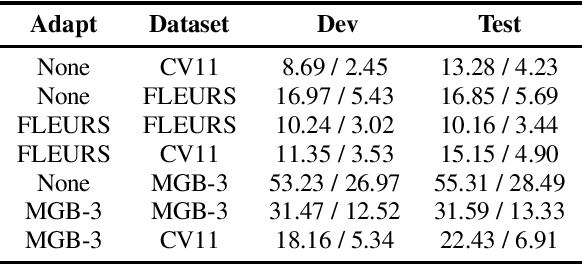
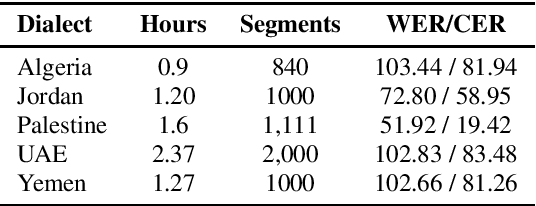
Whisper, the recently developed multilingual weakly supervised model, is reported to perform well on multiple speech recognition benchmarks in both monolingual and multilingual settings. However, it is not clear how Whisper would fare under diverse conditions even on languages it was evaluated on such as Arabic. In this work, we address this gap by comprehensively evaluating Whisper on several varieties of Arabic speech for the ASR task. Our evaluation covers most publicly available Arabic speech data and is performed under n-shot (zero-, few-, and full) finetuning. We also investigate the robustness of Whisper under completely novel conditions, such as in dialect-accented standard Arabic and in unseen dialects for which we develop evaluation data. Our experiments show that although Whisper zero-shot outperforms fully finetuned XLS-R models on all datasets, its performance deteriorates significantly in the zero-shot setting for five unseen dialects (i.e., Algeria, Jordan, Palestine, UAE, and Yemen).