 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMy Teacher Thinks The World Is Flat! Interpreting Automatic Essay Scoring Mechanism
Paper and Code
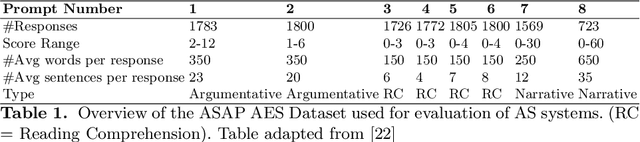
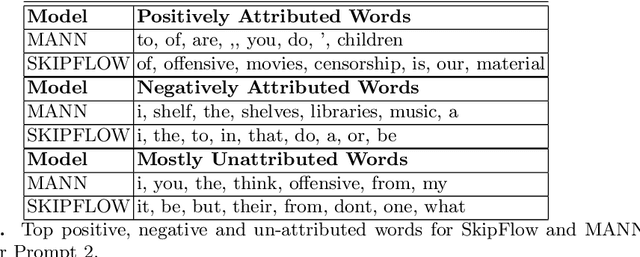
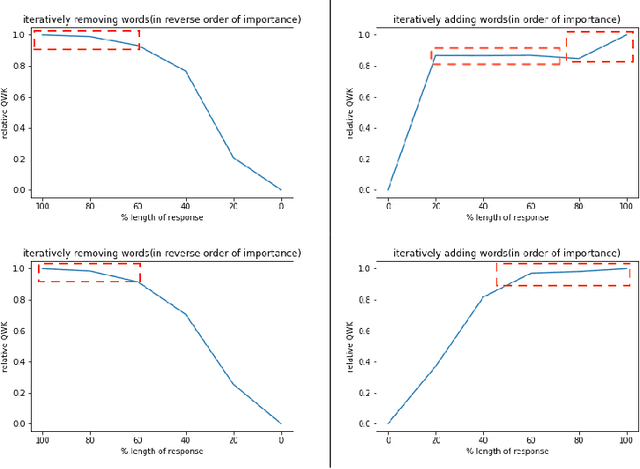

Significant progress has been made in deep-learning based Automatic Essay Scoring (AES) systems in the past two decades. However, little research has been put to understand and interpret the black-box nature of these deep-learning based scoring models. Recent work shows that automated scoring systems are prone to even common-sense adversarial samples. Their lack of natural language understanding capability raises questions on the models being actively used by millions of candidates for life-changing decisions. With scoring being a highly multi-modal task, it becomes imperative for scoring models to be validated and tested on all these modalities. We utilize recent advances in interpretability to find the extent to which features such as coherence, content and relevance are important for automated scoring mechanisms and why they are susceptible to adversarial samples. We find that the systems tested consider essays not as a piece of prose having the characteristics of natural flow of speech and grammatical structure, but as `word-soups' where a few words are much more important than the other words. Removing the context surrounding those few important words causes the prose to lose the flow of speech and grammar, however has little impact on the predicted score. We also find that since the models are not semantically grounded with world-knowledge and common sense, adding false facts such as ``the world is flat'' actually increases the score instead of decreasing it.