 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiview Transformers for Video Recognition
Paper and Code
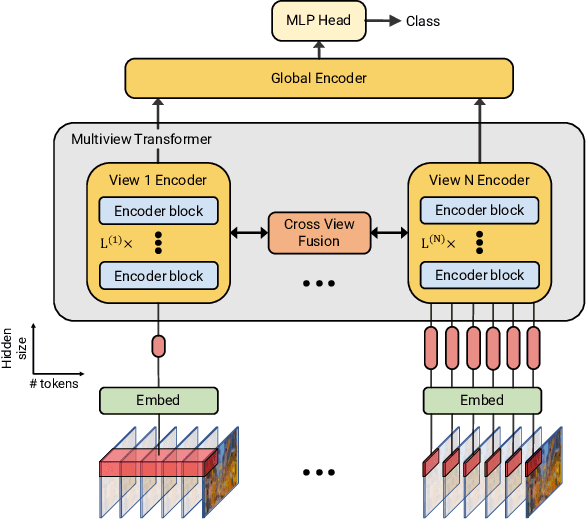
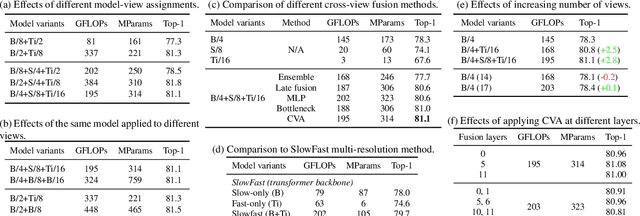
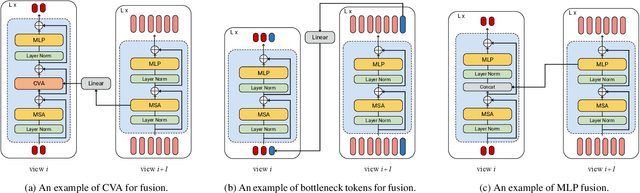
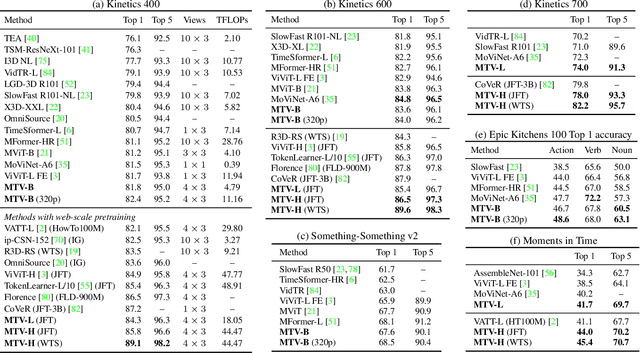
Video understanding requires reasoning at multiple spatiotemporal resolutions -- from short fine-grained motions to events taking place over longer durations. Although transformer architectures have recently advanced the state-of-the-art, they have not explicitly modelled different spatiotemporal resolutions. To this end, we present Multiview Transformers for Video Recognition (MTV). Our model consists of separate encoders to represent different views of the input video with lateral connections to fuse information across views. We present thorough ablation studies of our model and show that MTV consistently performs better than single-view counterparts in terms of accuracy and computational cost across a range of model sizes. Furthermore, we achieve state-of-the-art results on five standard datasets, and improve even further with large-scale pretraining. We will release code and pretrained checkpoints.