 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Probabilistic Model-Based Planning for Human-Robot Interaction
Paper and Code
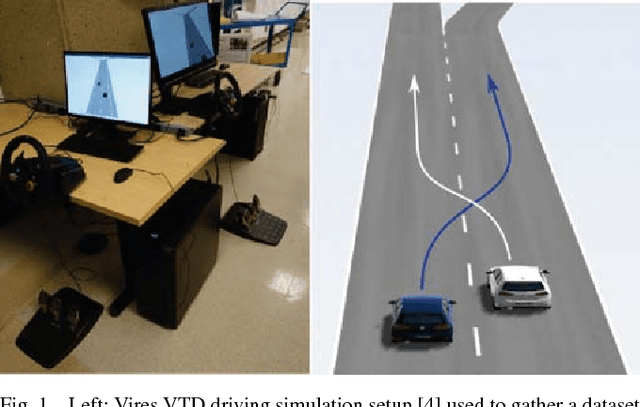
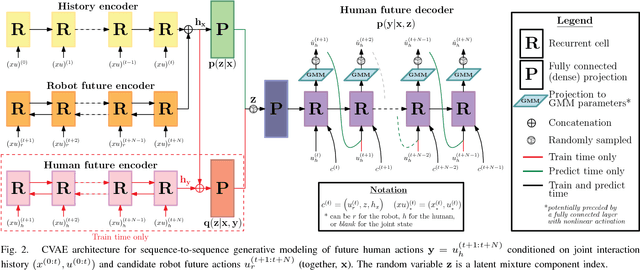
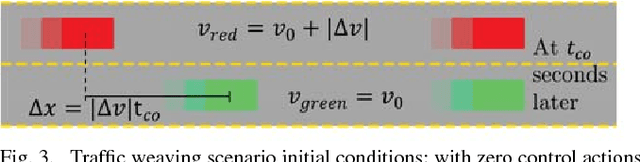
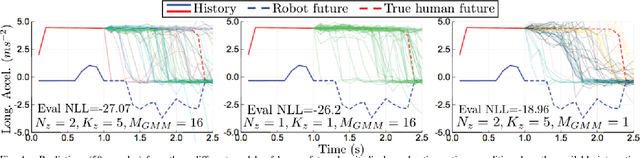
This paper presents a method for constructing human-robot interaction policies in settings where multimodality, i.e., the possibility of multiple highly distinct futures, plays a critical role in decision making. We are motivated in this work by the example of traffic weaving, e.g., at highway on-ramps/off-ramps, where entering and exiting cars must swap lanes in a short distance---a challenging negotiation even for experienced drivers due to the inherent multimodal uncertainty of who will pass whom. Our approach is to learn multimodal probability distributions over future human actions from a dataset of human-human exemplars and perform real-time robot policy construction in the resulting environment model through massively parallel sampling of human responses to candidate robot action sequences. Direct learning of these distributions is made possible by recent advances in the theory of conditional variational autoencoders (CVAEs), whereby we learn action distributions simultaneously conditioned on the present interaction history, as well as candidate future robot actions in order to take into account response dynamics. We demonstrate the efficacy of this approach with a human-in-the-loop simulation of a traffic weaving scenario.