 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Language Analysis with Recurrent Multistage Fusion
Paper and Code
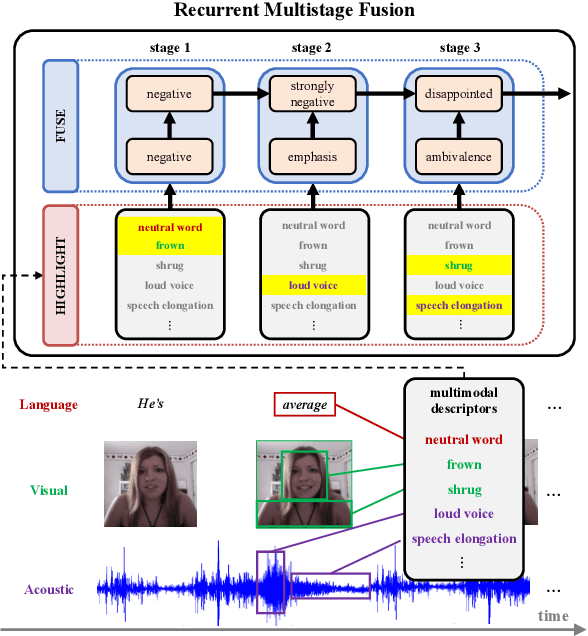
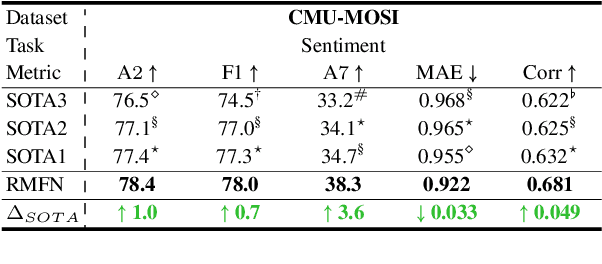
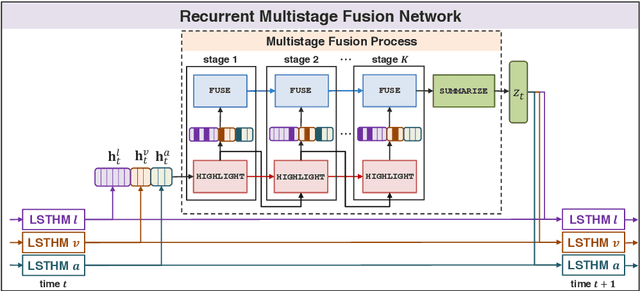
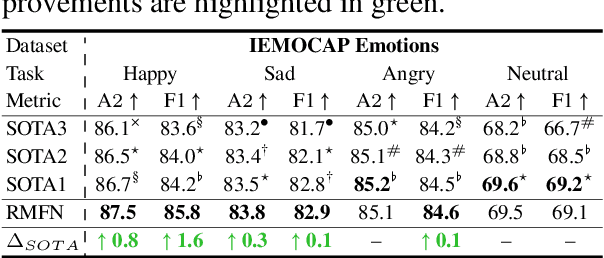
Computational modeling of human multimodal language is an emerging research area in natural language processing spanning the language, visual and acoustic modalities. Comprehending multimodal language requires modeling not only the interactions within each modality (intra-modal interactions) but more importantly the interactions between modalities (cross-modal interactions). In this paper, we propose the Recurrent Multistage Fusion Network (RMFN) which decomposes the fusion problem into multiple stages, each of them focused on a subset of multimodal signals for specialized, effective fusion. Cross-modal interactions are modeled using this multistage fusion approach which builds upon intermediate representations of previous stages. Temporal and intra-modal interactions are modeled by integrating our proposed fusion approach with a system of recurrent neural networks. The RMFN displays state-of-the-art performance in modeling human multimodal language across three public datasets relating to multimodal sentiment analysis, emotion recognition, and speaker traits recognition. We provide visualizations to show that each stage of fusion focuses on a different subset of multimodal signals, learning increasingly discriminative multimodal representations.