 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Information Interaction for Medical Image Segmentation
Paper and Code
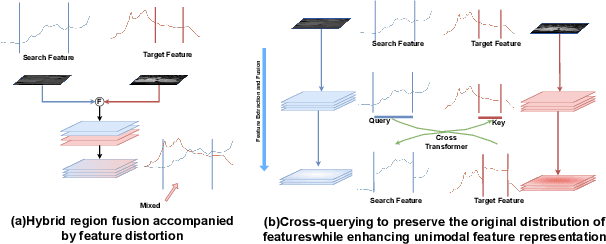
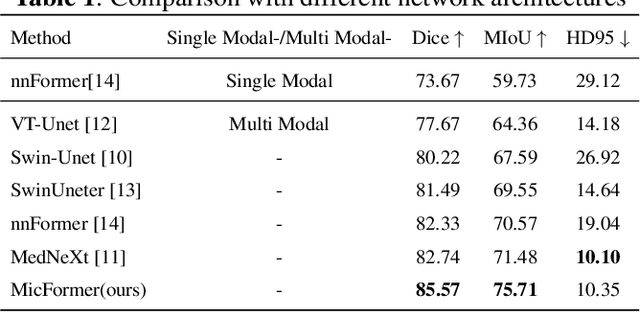
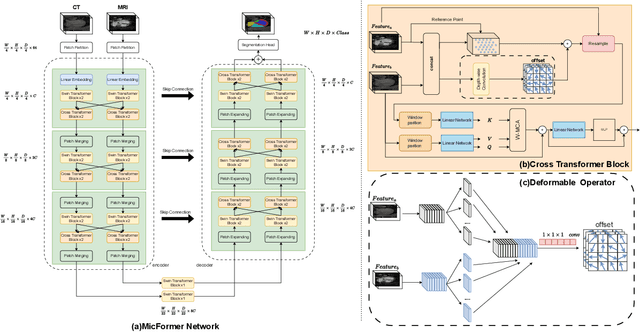
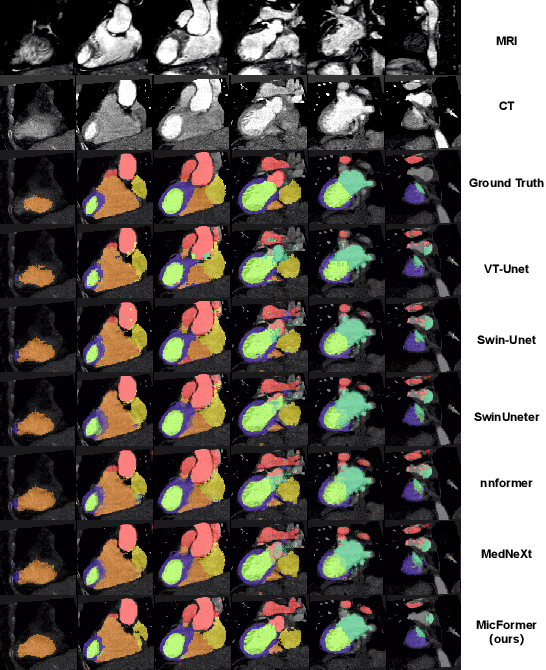
The use of multimodal data in assisted diagnosis and segmentation has emerged as a prominent area of interest in current research. However, one of the primary challenges is how to effectively fuse multimodal features. Most of the current approaches focus on the integration of multimodal features while ignoring the correlation and consistency between different modal features, leading to the inclusion of potentially irrelevant information. To address this issue, we introduce an innovative Multimodal Information Cross Transformer (MicFormer), which employs a dual-stream architecture to simultaneously extract features from each modality. Leveraging the Cross Transformer, it queries features from one modality and retrieves corresponding responses from another, facilitating effective communication between bimodal features. Additionally, we incorporate a deformable Transformer architecture to expand the search space. We conducted experiments on the MM-WHS dataset, and in the CT-MRI multimodal image segmentation task, we successfully improved the whole-heart segmentation DICE score to 85.57 and MIoU to 75.51. Compared to other multimodal segmentation techniques, our method outperforms by margins of 2.83 and 4.23, respectively. This demonstrates the efficacy of MicFormer in integrating relevant information between different modalities in multimodal tasks. These findings hold significant implications for multimodal image tasks, and we believe that MicFormer possesses extensive potential for broader applications across various domains. Access to our method is available at https://github.com/fxxJuses/MICFormer