 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Hierarchical Reinforcement Learning Policy for Task-Oriented Visual Dialog
Paper and Code
May 08, 2018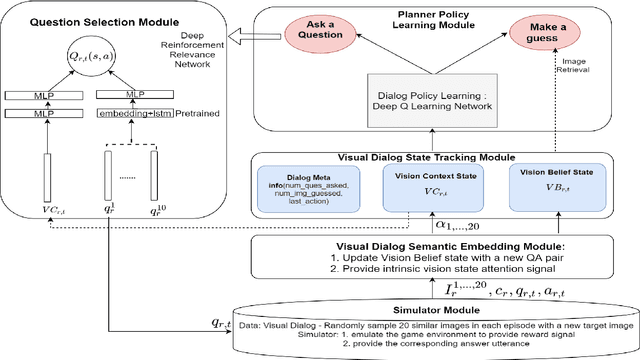
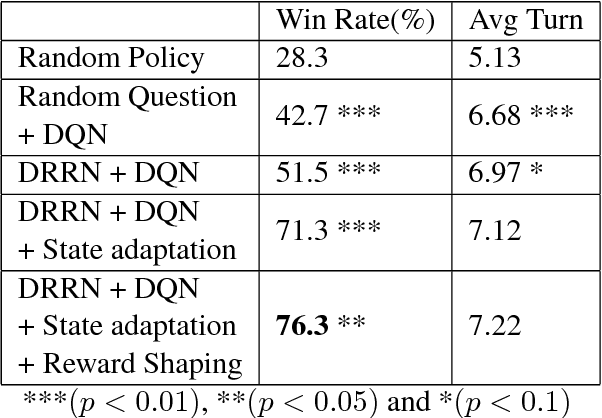
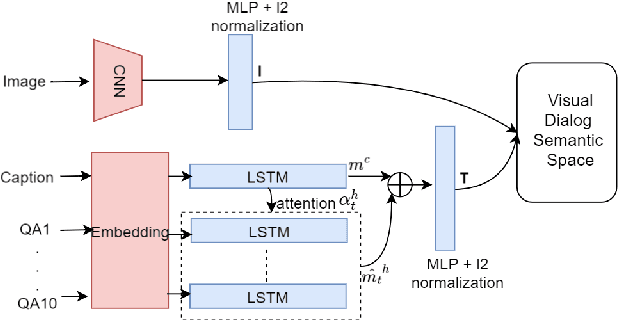

Creating an intelligent conversational system that understands vision and language is one of the ultimate goals in Artificial Intelligence (AI)~\cite{winograd1972understanding}. Extensive research has focused on vision-to-language generation, however, limited research has touched on combining these two modalities in a goal-driven dialog context. We propose a multimodal hierarchical reinforcement learning framework that dynamically integrates vision and language for task-oriented visual dialog. The framework jointly learns the multimodal dialog state representation and the hierarchical dialog policy to improve both dialog task success and efficiency. We also propose a new technique, state adaptation, to integrate context awareness in the dialog state representation. We evaluate the proposed framework and the state adaptation technique in an image guessing game and achieve promising results.