 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Data Fusion in High-Dimensional Heterogeneous Datasets via Generative Models
Paper and Code
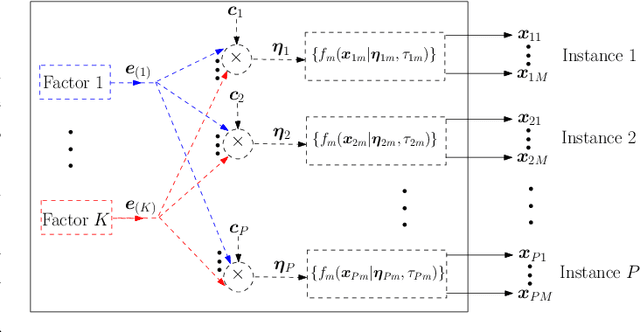
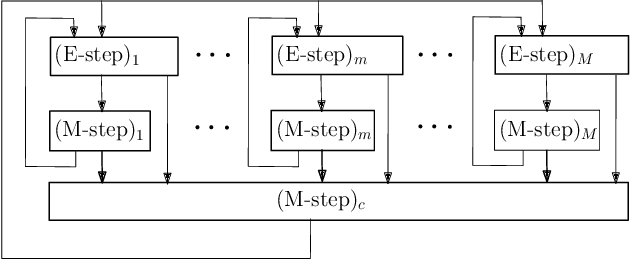
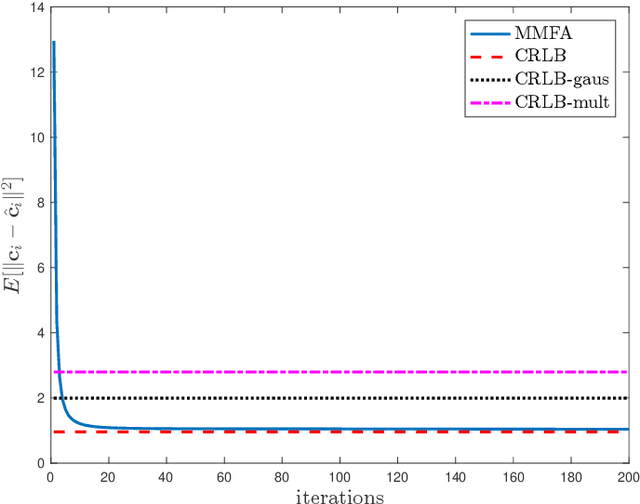
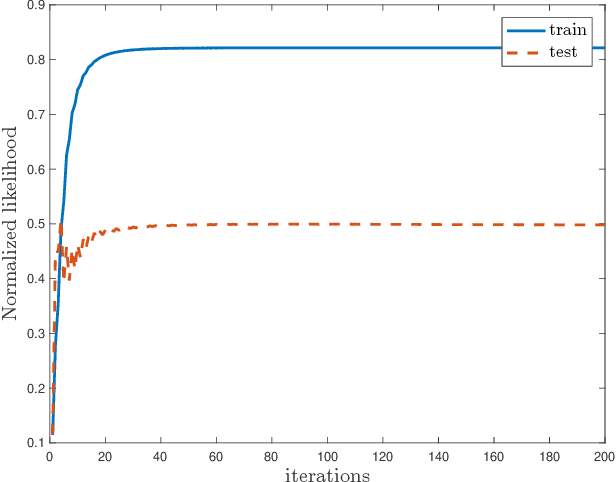
The commonly used latent space embedding techniques, such as Principal Component Analysis, Factor Analysis, and manifold learning techniques, are typically used for learning effective representations of homogeneous data. However, they do not readily extend to heterogeneous data that are a combination of numerical and categorical variables, e.g., arising from linked GPS and text data. In this paper, we are interested in learning probabilistic generative models from high-dimensional heterogeneous data in an unsupervised fashion. The learned generative model provides latent unified representations that capture the factors common to the multiple dimensions of the data, and thus enable fusing multimodal data for various machine learning tasks. Following a Bayesian approach, we propose a general framework that combines disparate data types through the natural parameterization of the exponential family of distributions. To scale the model inference to millions of instances with thousands of features, we use the Laplace-Bernstein approximation for posterior computations involving nonlinear link functions. The proposed algorithm is presented in detail for the commonly encountered heterogeneous datasets with real-valued (Gaussian) and categorical (multinomial) features. Experiments on two high-dimensional and heterogeneous datasets (NYC Taxi and MovieLens-10M) demonstrate the scalability and competitive performance of the proposed algorithm on different machine learning tasks such as anomaly detection, data imputation, and recommender systems.