 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Part-of-Speech Tagging: Two Unsupervised Approaches
Paper and Code
Jan 15, 2014
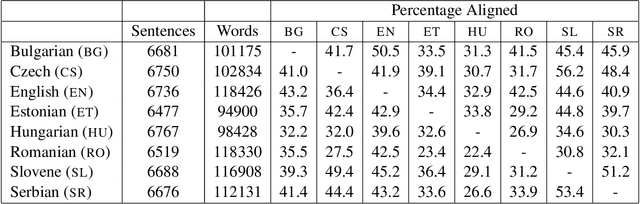

We demonstrate the effectiveness of multilingual learning for unsupervised part-of-speech tagging. The central assumption of our work is that by combining cues from multiple languages, the structure of each becomes more apparent. We consider two ways of applying this intuition to the problem of unsupervised part-of-speech tagging: a model that directly merges tag structures for a pair of languages into a single sequence and a second model which instead incorporates multilingual context using latent variables. Both approaches are formulated as hierarchical Bayesian models, using Markov Chain Monte Carlo sampling techniques for inference. Our results demonstrate that by incorporating multilingual evidence we can achieve impressive performance gains across a range of scenarios. We also found that performance improves steadily as the number of available languages increases.