 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Multiaccented Multispeaker TTS with RADTTS
Paper and Code
Jan 24, 2023
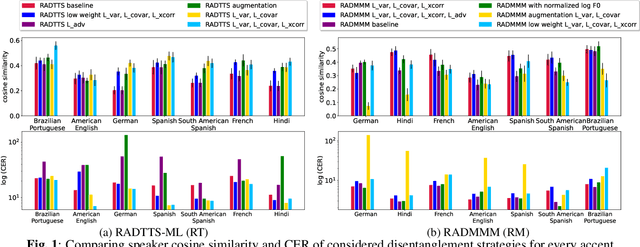
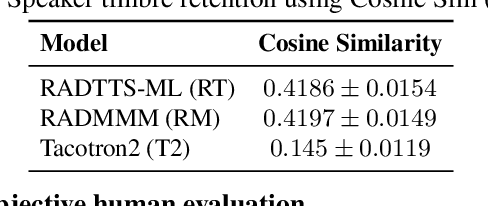
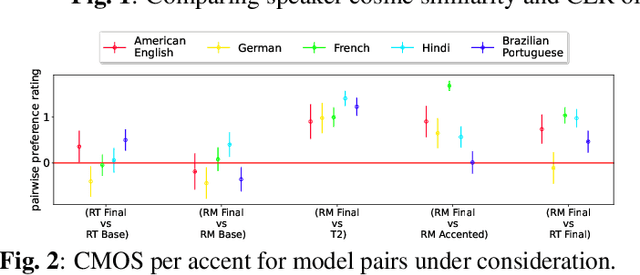
We work to create a multilingual speech synthesis system which can generate speech with the proper accent while retaining the characteristics of an individual voice. This is challenging to do because it is expensive to obtain bilingual training data in multiple languages, and the lack of such data results in strong correlations that entangle speaker, language, and accent, resulting in poor transfer capabilities. To overcome this, we present a multilingual, multiaccented, multispeaker speech synthesis model based on RADTTS with explicit control over accent, language, speaker and fine-grained $F_0$ and energy features. Our proposed model does not rely on bilingual training data. We demonstrate an ability to control synthesized accent for any speaker in an open-source dataset comprising of 7 accents. Human subjective evaluation demonstrates that our model can better retain a speaker's voice and accent quality than controlled baselines while synthesizing fluent speech in all target languages and accents in our dataset.