 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual ColBERT-X
Paper and Code

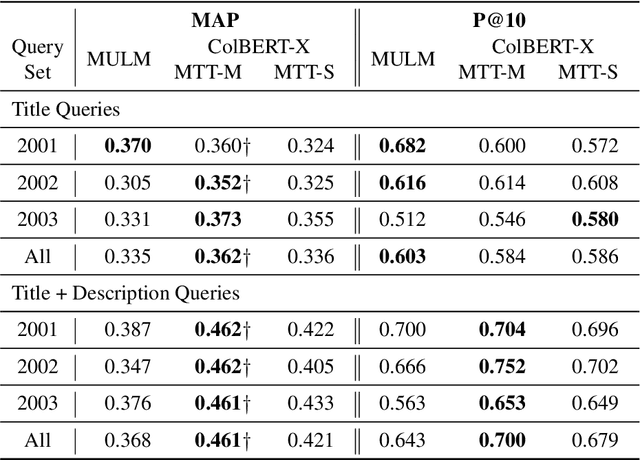
ColBERT-X is a dense retrieval model for Cross Language Information Retrieval (CLIR). In CLIR, documents are written in one natural language, while the queries are expressed in another. A related task is multilingual IR (MLIR) where the system creates a single ranked list of documents written in many languages. Given that ColBERT-X relies on a pretrained multilingual neural language model to rank documents, a multilingual training procedure can enable a version of ColBERT-X well-suited for MLIR. This paper describes that training procedure. An important factor for good MLIR ranking is fine-tuning XLM-R using mixed-language batches, where the same query is matched with documents in different languages in the same batch. Neural machine translations of MS MARCO passages are used to fine-tune the model.