 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual ASR with Massive Data Augmentation
Paper and Code
Sep 14, 2019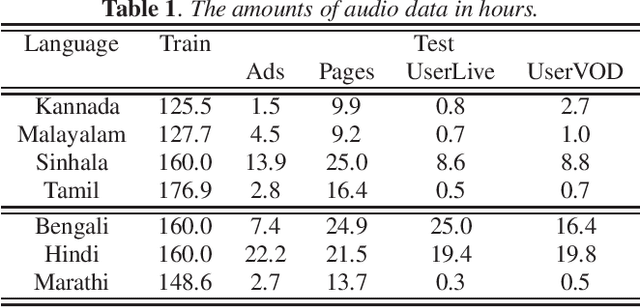
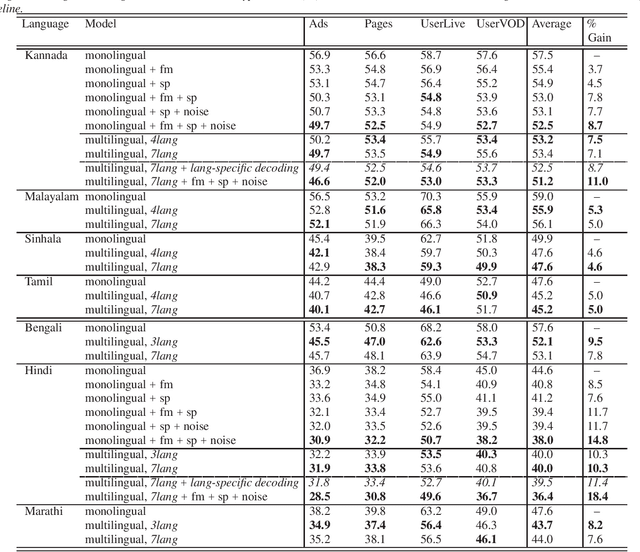
Towards developing high-performing ASR for low-resource languages, approaches to address the lack of resources are to make use of data from multiple languages, and to augment the training data by creating acoustic variations. In this work we present a single grapheme-based ASR model learned on 7 geographically proximal languages, using standard hybrid BLSTM-HMM acoustic models with lattice-free MMI objective. We build the single ASR grapheme set via taking the union over each language-specific grapheme set, and we find such multilingual ASR model can perform language-independent recognition on all 7 languages, and substantially outperform each monolingual ASR model. Secondly, we evaluate the efficacy of multiple data augmentation alternatives within language, as well as their complementarity with multilingual modeling. Overall, we show that the proposed multilingual ASR with various data augmentation can not only recognize any within training set languages, but also provide large ASR performance improvements.