 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultichannel Semantic Segmentation with Unsupervised Domain Adaptation
Paper and Code
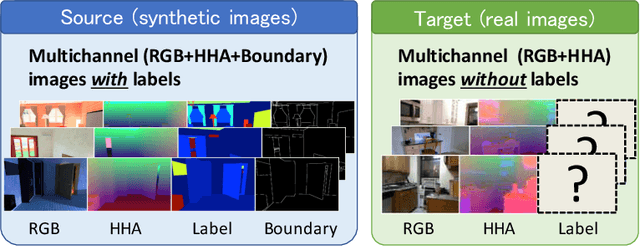
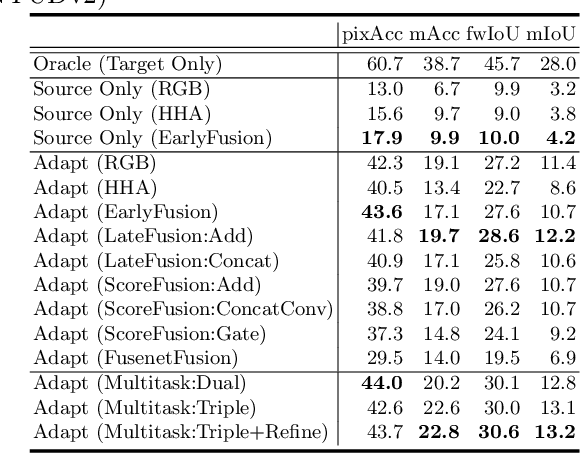
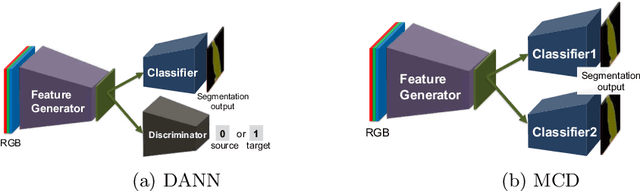
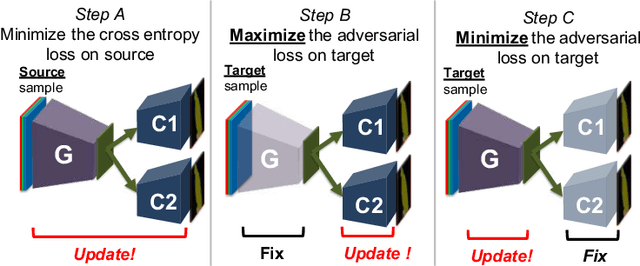
Most contemporary robots have depth sensors, and research on semantic segmentation with RGBD images has shown that depth images boost the accuracy of segmentation. Since it is time-consuming to annotate images with semantic labels per pixel, it would be ideal if we could avoid this laborious work by utilizing an existing dataset or a synthetic dataset which we can generate on our own. Robot motions are often tested in a synthetic environment, where multichannel (eg, RGB + depth + instance boundary) images plus their pixel-level semantic labels are available. However, models trained simply on synthetic images tend to demonstrate poor performance on real images. In order to address this, we propose two approaches that can efficiently exploit multichannel inputs combined with an unsupervised domain adaptation (UDA) algorithm. One is a fusion-based approach that uses depth images as inputs. The other is a multitask learning approach that uses depth images as outputs. We demonstrated that the segmentation results were improved by using a multitask learning approach with a post-process and created a benchmark for this task.