 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-view (Joint) Probability Linear Discrimination Analysis for Multi-view Feature Verification
Paper and Code
Jul 07, 2017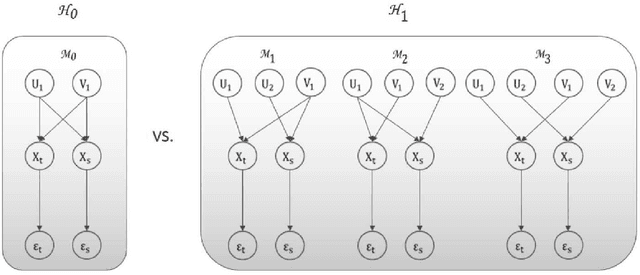
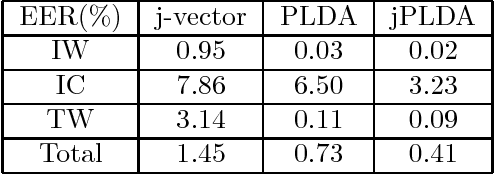
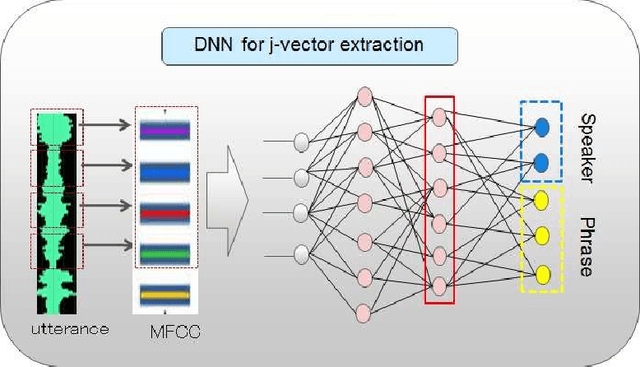
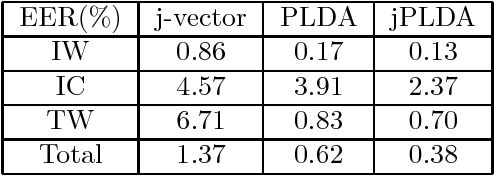
Multi-view feature has been proved to be very effective in many multimedia applications. However, the current back-end classifiers cannot make full use of such features. In this paper, we propose a method to model the multi-faceted information in the multi-view features explicitly and jointly. In our approach, the feature was modeled as a result derived by a generative multi-view (joint\footnotemark[1]) Probability Linear Discriminant Analysis (PLDA) model, which contains multiple kinds of latent variables. The usual PLDA model only considers one single label. However, in practical use, when using multi-task learned network as feature extractor, the extracted feature are always attached to several labels. This type of feature is called multi-view feature. With multi-view (joint) PLDA, we are able to explicitly build a model that can combine multiple heterogeneous information from the multi-view features. In verification step, we calculated the likelihood to describe whether the two features having consistent labels or not. This likelihood are used in the following decision-making. Experiments have been conducted on large scale verification task. On the public RSR2015 data corpus, the results showed that our approach can achieve 0.02\% EER and 0.09\% EER for impostor wrong and impostor correct cases respectively.