 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-granularity Generator for Temporal Action Proposal
Paper and Code
Nov 28, 2018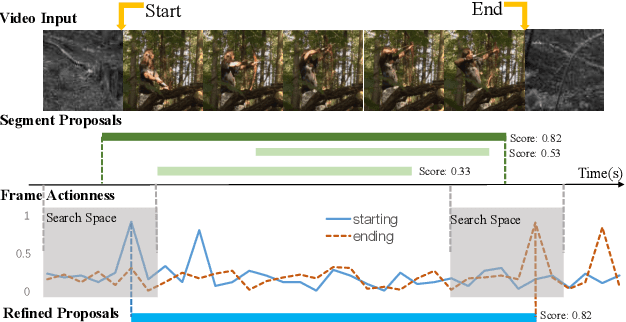



Temporal action proposal generation is an important task, aiming to localize the video segments containing human actions in an untrimmed video. In this paper, we propose a multi-granularity generator (MGG) to perform the temporal action proposal from different granularity perspectives, relying on the video visual features equipped with the position embedding information. First, we propose to use a bilinear matching model to exploit the rich local information within the video sequence. Afterwards, two components, namely segment proposal generator (SPG) and frame actionness generator (FAG), are combined to perform the task of temporal action proposal at two distinct granularities. SPG considers the whole video in the form of feature pyramid and generates segment proposals from one coarse perspective, while FAG carries out a finer actionness evaluation for each video frame. Our proposed MGG can be trained in an end-to-end fashion. Through temporally adjusting the segment proposals with fine-grained information based on frame actionness, MGG achieves the superior performance over state-of-the-art methods on the public THUMOS-14 and ActivityNet-1.3 datasets. Moreover, we employ existing action classifiers to perform the classification of the proposals generated by MGG, leading to significant improvements compared against the competing methods for the video detection task.