 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Armed Bandits with Dependent Arms
Paper and Code
Oct 23, 2020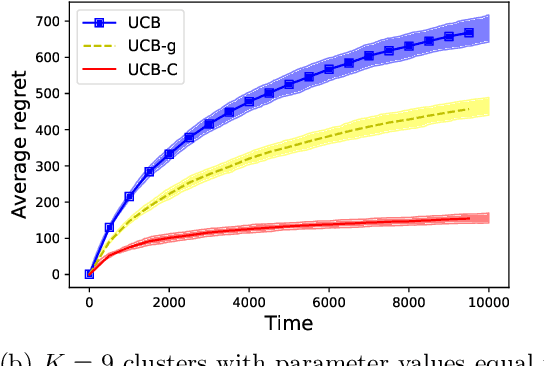
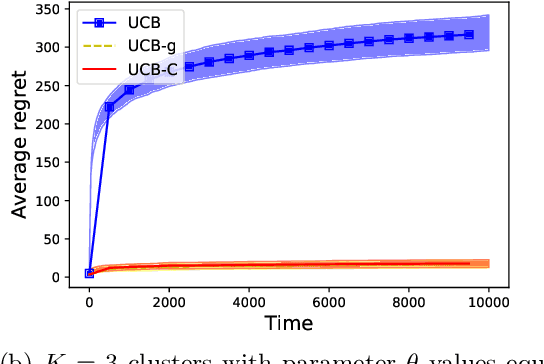
We study a variant of the classical multi-armed bandit problem (MABP) which we call as Multi-Armed Bandits with dependent arms. More specifically, multiple arms are grouped together to form a cluster, and the reward distributions of arms belonging to the same cluster are known functions of an unknown parameter that is a characteristic of the cluster. Thus, pulling an arm $i$ not only reveals information about its own reward distribution, but also about all those arms that share the same cluster with arm $i$. This "correlation" amongst the arms complicates the exploration-exploitation trade-off that is encountered in the MABP because the observation dependencies allow us to test simultaneously multiple hypotheses regarding the optimality of an arm. We develop learning algorithms based on the UCB principle which utilize these additional side observations appropriately while performing exploration-exploitation trade-off. We show that the regret of our algorithms grows as $O(K\log T)$, where $K$ is the number of clusters. In contrast, for an algorithm such as the vanilla UCB that is optimal for the classical MABP and does not utilize these dependencies, the regret scales as $O(M\log T)$ where $M$ is the number of arms.