 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Embodied Visual Semantic Navigation with Scene Prior Knowledge
Paper and Code
Sep 20, 2021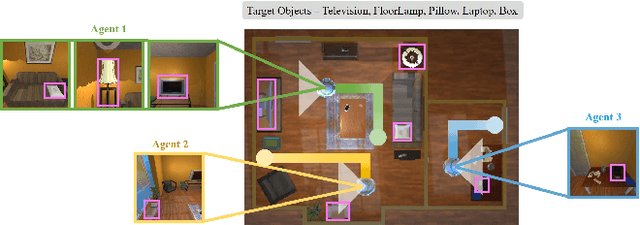
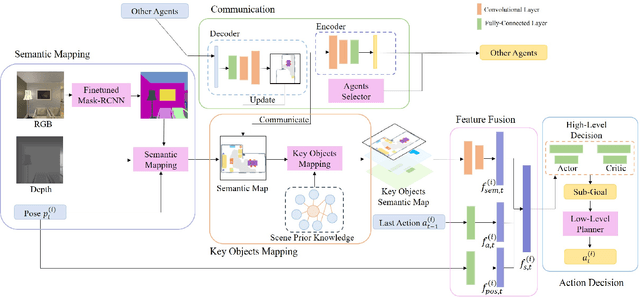
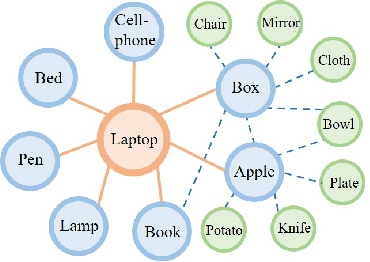

In visual semantic navigation, the robot navigates to a target object with egocentric visual observations and the class label of the target is given. It is a meaningful task inspiring a surge of relevant research. However, most of the existing models are only effective for single-agent navigation, and a single agent has low efficiency and poor fault tolerance when completing more complicated tasks. Multi-agent collaboration can improve the efficiency and has strong application potentials. In this paper, we propose the multi-agent visual semantic navigation, in which multiple agents collaborate with others to find multiple target objects. It is a challenging task that requires agents to learn reasonable collaboration strategies to perform efficient exploration under the restrictions of communication bandwidth. We develop a hierarchical decision framework based on semantic mapping, scene prior knowledge, and communication mechanism to solve this task. The results of testing experiments in unseen scenes with both known objects and unknown objects illustrate the higher accuracy and efficiency of the proposed model compared with the single-agent model.