 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Advisor Q-Learning
Paper and Code

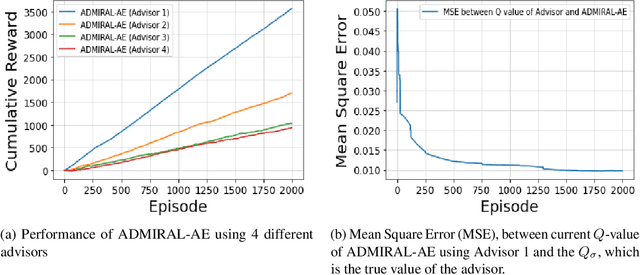
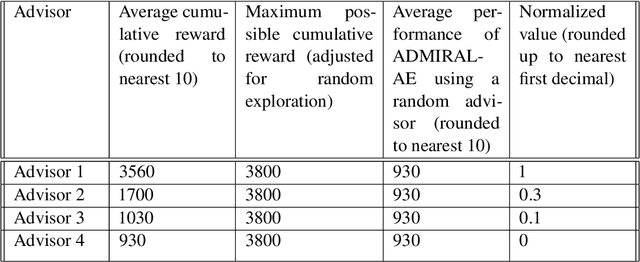
In the last decade, there have been significant advances in multi-agent reinforcement learning (MARL) but there are still numerous challenges, such as high sample complexity and slow convergence to stable policies, that need to be overcome before wide-spread deployment is possible. However, many real-world environments already, in practice, deploy sub-optimal or heuristic approaches for generating policies. An interesting question which arises is how to best use such approaches as advisors to help improve reinforcement learning in multi-agent domains. In this paper, we provide a principled framework for incorporating action recommendations from online sub-optimal advisors in multi-agent settings. We describe the problem of ADvising Multiple Intelligent Reinforcement Agents (ADMIRAL) in nonrestrictive general-sum stochastic game environments and present two novel Q-learning based algorithms: ADMIRAL - Decision Making (ADMIRAL-DM) and ADMIRAL - Advisor Evaluation (ADMIRAL-AE), which allow us to improve learning by appropriately incorporating advice from an advisor (ADMIRAL-DM), and evaluate the effectiveness of an advisor (ADMIRAL-AE). We analyze the algorithms theoretically and provide fixed-point guarantees regarding their learning in general-sum stochastic games. Furthermore, extensive experiments illustrate that these algorithms: can be used in a variety of environments, have performances that compare favourably to other related baselines, can scale to large state-action spaces, and are robust to poor advice from advisors.