 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMT-UDA: Towards Unsupervised Cross-modality Medical Image Segmentation with Limited Source Labels
Paper and Code
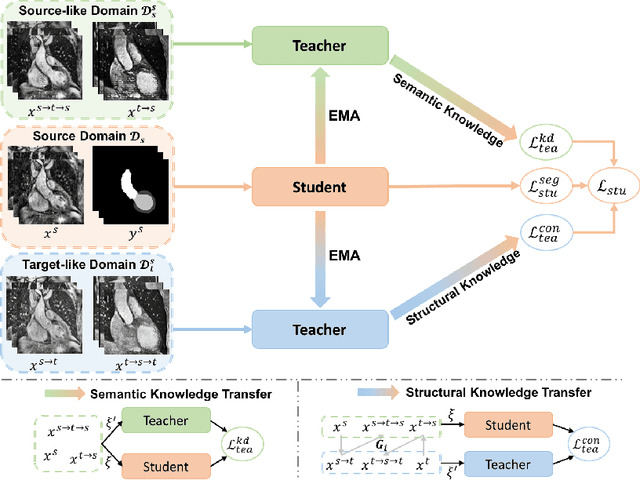
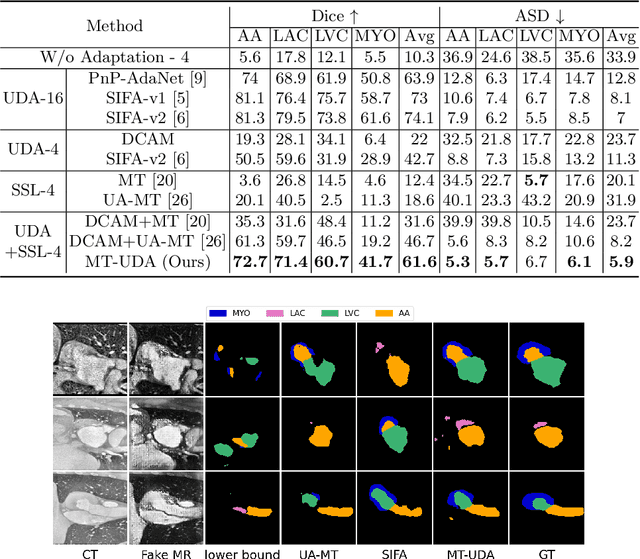
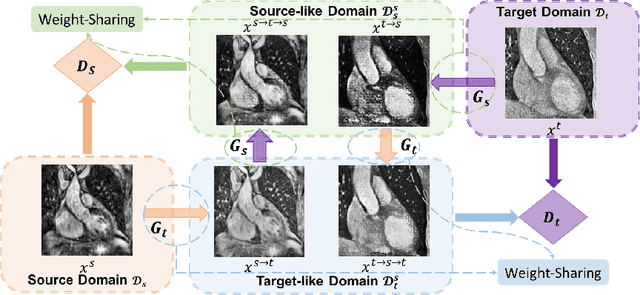
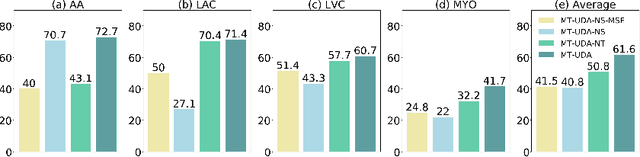
The success of deep convolutional neural networks (DCNNs) benefits from high volumes of annotated data. However, annotating medical images is laborious, expensive, and requires human expertise, which induces the label scarcity problem. Especially when encountering the domain shift, the problem becomes more serious. Although deep unsupervised domain adaptation (UDA) can leverage well-established source domain annotations and abundant target domain data to facilitate cross-modality image segmentation and also mitigate the label paucity problem on the target domain, the conventional UDA methods suffer from severe performance degradation when source domain annotations are scarce. In this paper, we explore a challenging UDA setting - limited source domain annotations. We aim to investigate how to efficiently leverage unlabeled data from the source and target domains with limited source annotations for cross-modality image segmentation. To achieve this, we propose a new label-efficient UDA framework, termed MT-UDA, in which the student model trained with limited source labels learns from unlabeled data of both domains by two teacher models respectively in a semi-supervised manner. More specifically, the student model not only distills the intra-domain semantic knowledge by encouraging prediction consistency but also exploits the inter-domain anatomical information by enforcing structural consistency. Consequently, the student model can effectively integrate the underlying knowledge beneath available data resources to mitigate the impact of source label scarcity and yield improved cross-modality segmentation performance. We evaluate our method on MM-WHS 2017 dataset and demonstrate that our approach outperforms the state-of-the-art methods by a large margin under the source-label scarcity scenario.