 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSAF: Multimodal Split Attention Fusion
Paper and Code
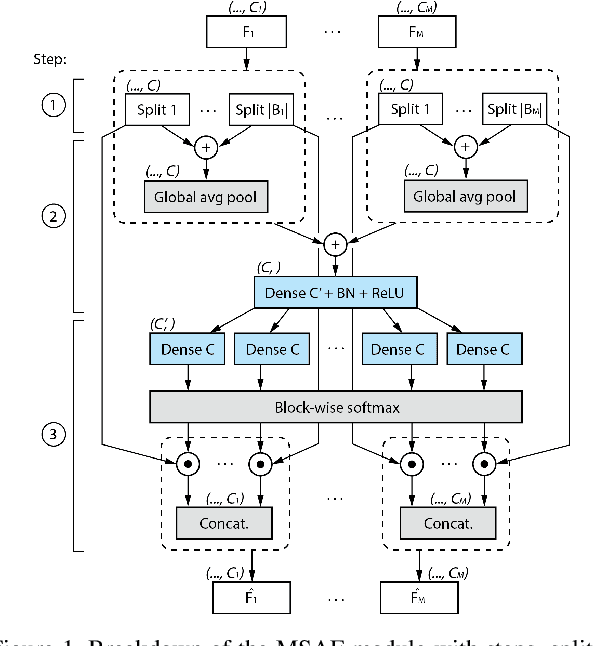

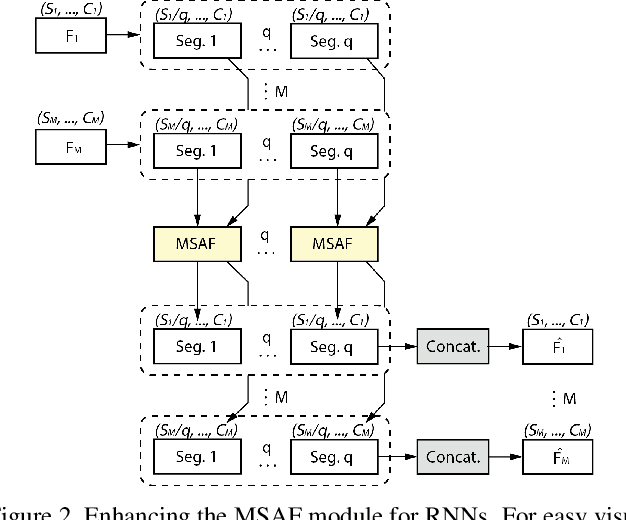
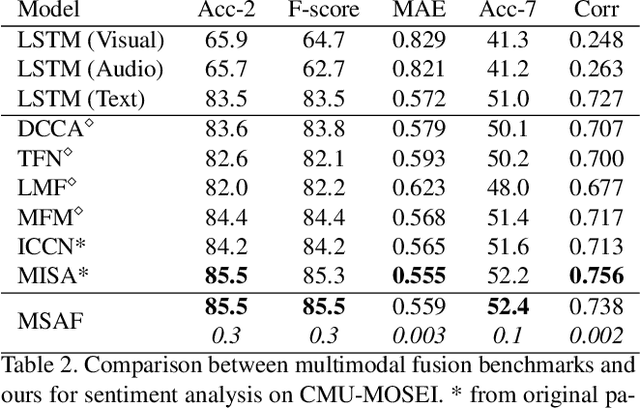
Multimodal learning mimics the reasoning process of the human multi-sensory system, which is used to perceive the surrounding world. While making a prediction, the human brain tends to relate crucial cues from multiple sources of information. In this work, we propose a novel multimodal fusion module that learns to emphasize more contributive features across all modalities. Specifically, the proposed Multimodal Split Attention Fusion (MSAF) module splits each modality into channel-wise equal feature blocks and creates a joint representation that is used to generate soft attention for each channel across the feature blocks. Further, the MSAF module is designed to be compatible with features of various spatial dimensions and sequence lengths, suitable for both CNNs and RNNs. Thus, MSAF can be easily added to fuse features of any unimodal networks and utilize existing pretrained unimodal model weights. To demonstrate the effectiveness of our fusion module, we design three multimodal networks with MSAF for emotion recognition, sentiment analysis, and action recognition tasks. Our approach achieves competitive results in each task and outperforms other application-specific networks and multimodal fusion benchmarks.