 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMovie Question Answering: Remembering the Textual Cues for Layered Visual Contents
Paper and Code
Apr 25, 2018

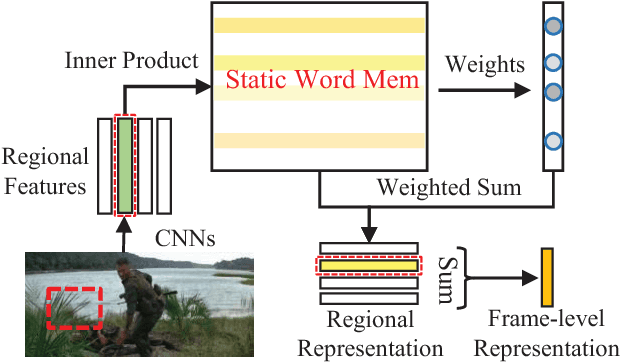

Movies provide us with a mass of visual content as well as attracting stories. Existing methods have illustrated that understanding movie stories through only visual content is still a hard problem. In this paper, for answering questions about movies, we put forward a Layered Memory Network (LMN) that represents frame-level and clip-level movie content by the Static Word Memory module and the Dynamic Subtitle Memory module, respectively. Particularly, we firstly extract words and sentences from the training movie subtitles. Then the hierarchically formed movie representations, which are learned from LMN, not only encode the correspondence between words and visual content inside frames, but also encode the temporal alignment between sentences and frames inside movie clips. We also extend our LMN model into three variant frameworks to illustrate the good extendable capabilities. We conduct extensive experiments on the MovieQA dataset. With only visual content as inputs, LMN with frame-level representation obtains a large performance improvement. When incorporating subtitles into LMN to form the clip-level representation, we achieve the state-of-the-art performance on the online evaluation task of 'Video+Subtitles'. The good performance successfully demonstrates that the proposed framework of LMN is effective and the hierarchically formed movie representations have good potential for the applications of movie question answering.