 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotron: Multimodal Probabilistic Human Motion Forecasting
Paper and Code


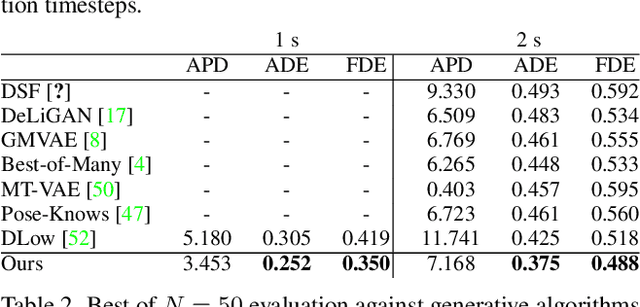
Autonomous systems and humans are increasingly sharing the same space. Robots work side by side or even hand in hand with humans to balance each other's limitations. Such cooperative interactions are ever more sophisticated. Thus, the ability to reason not just about a human's center of gravity position, but also its granular motion is an important prerequisite for human-robot interaction. Though, many algorithms ignore the multimodal nature of humans or neglect uncertainty in their motion forecasts. We present Motron, a multimodal, probabilistic, graph-structured model, that captures human's multimodality using probabilistic methods while being able to output deterministic maximum-likelihood motions and corresponding confidence values for each mode. Our model aims to be tightly integrated with the robotic planning-control-interaction loop; outputting physically feasible human motions and being computationally efficient. We demonstrate the performance of our model on several challenging real-world motion forecasting datasets, outperforming a wide array of generative/variational methods while providing state-of-the-art single-output motions if required. Both using significantly less computational power than state-of-the art algorithms.