 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotionLLM: Multimodal Motion-Language Learning with Large Language Models
Paper and Code


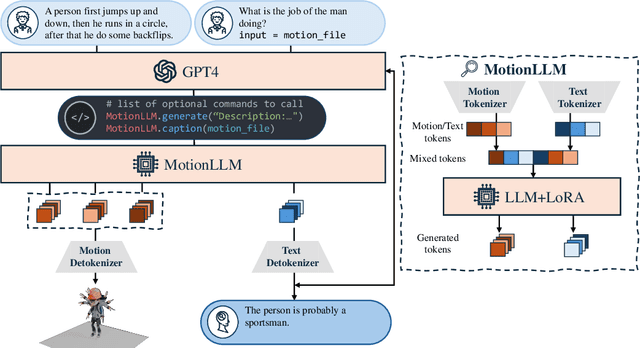
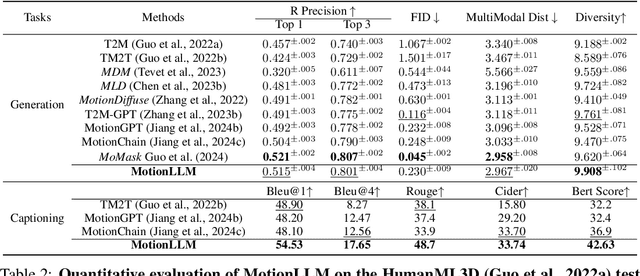
Recent advancements in Multimodal Large Language Models (MM-LLMs) have demonstrated promising potential in terms of generalization and robustness when applied to different modalities. While previous works have already achieved 3D human motion generation using various approaches including language modeling, they mostly % are mostly carefully designed use specialized architecture and are restricted to single-human motion generation. Inspired by the success of MM-LLMs, we propose MotionLLM, a simple and general framework that can achieve single-human, multi-human motion generation, and motion captioning by fine-tuning pre-trained LLMs. Specifically, we encode and quantize motions into discrete LLM-understandable tokens, which results in a unified vocabulary consisting of both motion and text tokens. With only 1--3% parameters of the LLMs trained by using adapters, our single-human motion generation achieves comparable results to those diffusion models and other trained-from-scratch transformer-based models. Additionally, we show that our approach is scalable and flexible, allowing easy extension to multi-human motion generation through autoregressive generation of single-human motions. Project page: https://knoxzhao.github.io/MotionLLM