 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion-Focused Contrastive Learning of Video Representations
Paper and Code

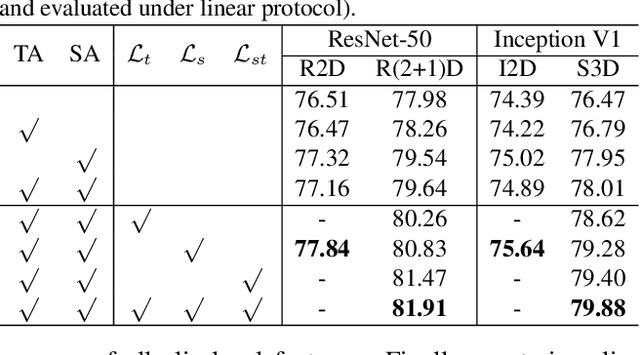
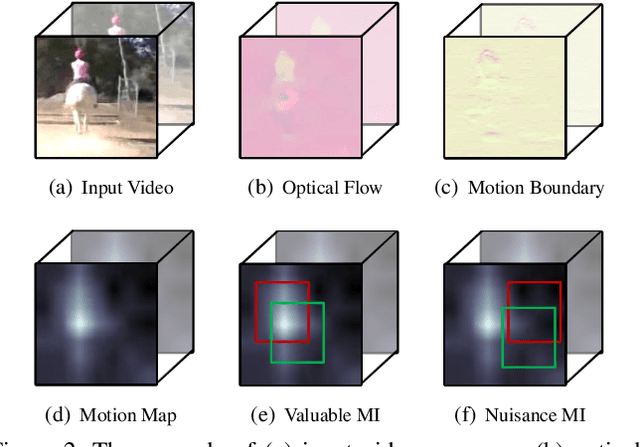

Motion, as the most distinct phenomenon in a video to involve the changes over time, has been unique and critical to the development of video representation learning. In this paper, we ask the question: how important is the motion particularly for self-supervised video representation learning. To this end, we compose a duet of exploiting the motion for data augmentation and feature learning in the regime of contrastive learning. Specifically, we present a Motion-focused Contrastive Learning (MCL) method that regards such duet as the foundation. On one hand, MCL capitalizes on optical flow of each frame in a video to temporally and spatially sample the tubelets (i.e., sequences of associated frame patches across time) as data augmentations. On the other hand, MCL further aligns gradient maps of the convolutional layers to optical flow maps from spatial, temporal and spatio-temporal perspectives, in order to ground motion information in feature learning. Extensive experiments conducted on R(2+1)D backbone demonstrate the effectiveness of our MCL. On UCF101, the linear classifier trained on the representations learnt by MCL achieves 81.91% top-1 accuracy, outperforming ImageNet supervised pre-training by 6.78%. On Kinetics-400, MCL achieves 66.62% top-1 accuracy under the linear protocol. Code is available at https://github.com/YihengZhang-CV/MCL-Motion-Focused-Contrastive-Learning.