 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Communication Does Not Result in Smaller Generalization Error in Federated Learning
Paper and Code
Apr 24, 2023
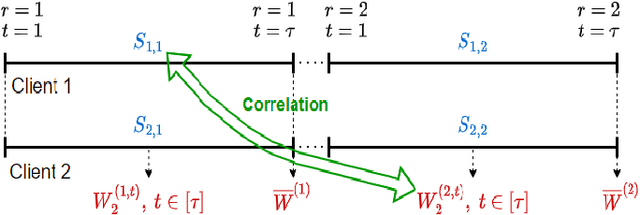
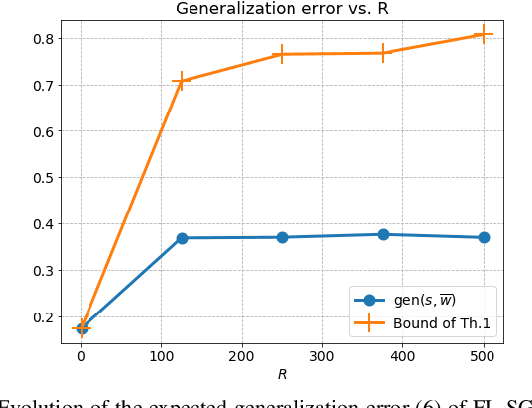
We study the generalization error of statistical learning models in a Federated Learning (FL) setting. Specifically, there are $K$ devices or clients, each holding an independent own dataset of size $n$. Individual models, learned locally via Stochastic Gradient Descent, are aggregated (averaged) by a central server into a global model and then sent back to the devices. We consider multiple (say $R \in \mathbb N^*$) rounds of model aggregation and study the effect of $R$ on the generalization error of the final aggregated model. We establish an upper bound on the generalization error that accounts explicitly for the effect of $R$ (in addition to the number of participating devices $K$ and dataset size $n$). It is observed that, for fixed $(n, K)$, the bound increases with $R$, suggesting that the generalization of such learning algorithms is negatively affected by more frequent communication with the parameter server. Combined with the fact that the empirical risk, however, generally decreases for larger values of $R$, this indicates that $R$ might be a parameter to optimize to reduce the population risk of FL algorithms. The results of this paper, which extend straightforwardly to the heterogeneous data setting, are also illustrated through numerical examples.